使用Unigram语言模型(ULM)优化分词算法:核心思路与实践
元数据
- 分类:自然语言处理(NLP)
- 标签:Unigram语言模型、分词算法、BPE、子词优化
- 日期:2025年4月2日
核心观点总结
Unigram语言模型(ULM)是一种基于概率的分词算法,通过逐步优化词表,保留对整体损失影响较大的子词,从而生成更优的分词结果。其核心思想是利用语言模型的概率分布来衡量子词的重要性,最终构建一个高效且覆盖全面的词表。
重点内容解析
1. ULM的核心思路
ULM通过以下步骤实现子词优化:
✅ 初始化大词表:创建一个包含所有字符和高频n-gram的初始词表,确保覆盖语料中的所有单词。可以利用BPE(Byte Pair Encoding)等方法构建。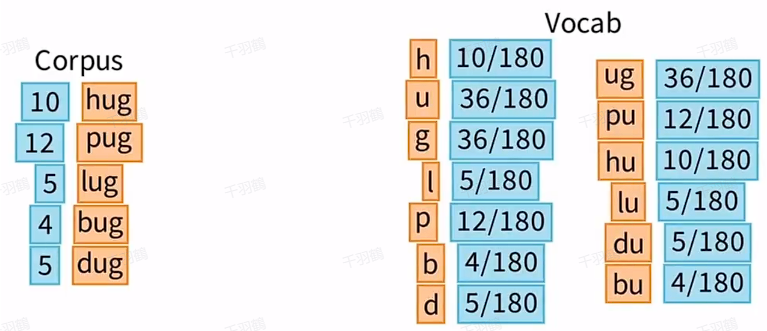
✅ 计算子词概率:使用Unigram语言模型(如EM算法)估计每个子词的概率,并通过维特比算法寻找最优分词结果。
✅ 评估子词重要性:计算删除每个子词对总损失(Loss)的影响,重要性越高的子词对Loss的影响越大。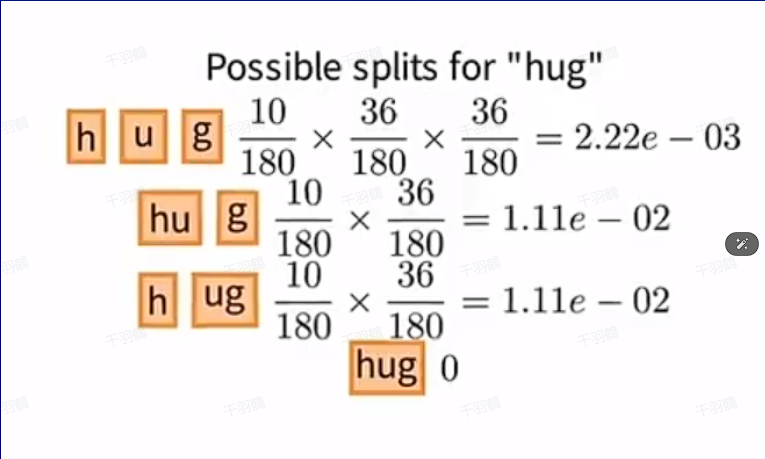
✅ 精简词表:按照Loss大小排序,移除对Loss影响最小的子词,重复上述步骤,直到词表缩减到目标大小。
2. ULM的优势与挑战
| 优势 💡 | 挑战 ⚠️ |
|---|---|
| 利用所有可能的分词结果,提高分词质量 | 初始词表质量对结果影响显著 |
| 能为多种分词结果赋予概率,处理噪声能力强 | 算法实现较复杂 |
| 支持生成带概率的分词结果,提高灵活性 | 需要大量计算资源 |
3. ULM操作流程示例
以下是一个基于"hug"单词的具体操作示例:
- 初始分词方法:对于"hug",可能有以下分词方式:
h,u,ghu,gh,ughug(不在初始词表中)
- 概率计算:
- 假设前三种分词方式在初始词表中,其概率分别为:
P(h,u,g) = 0.005,P(hu,g) = 0.006,P(h,ug) = 0.011。
- 假设前三种分词方式在初始词表中,其概率分别为:
- 选择最优分词:
- 根据最大似然原则,选择
P(h,ug) = 0.011作为最优分词结果。
- 根据最大似然原则,选择
4. 数据与趋势📈
以下是ULM优化过程中需要关注的数据点:
| 数据点 | 示例值 |
|---|---|
| 初始Loss总值 | 170.40 |
子词ug的使用频率 |
0 |
子词ug对Loss影响 |
最小 |
📈 趋势预测:随着迭代次数增加,低频或无用子词将逐步被移除,最终形成一个高效的紧凑型词表。
5. 常见错误⚠️
- 删除单字符子词:由于单字符子词是语料覆盖的基础,它们不能被移除,否则会导致OOV(Out of Vocabulary)问题。
- 初始词表不完整:如果初始词表不能覆盖语料中的所有单词,后续概率计算将失败。
行动清单
- 📌 使用BPE或字符级初始化构建大规模初始词表。
- 📌 实现基于Unigram模型的EM算法,用于子词概率估计。
- 📌 开发自动化流程,定期评估和精简子词表。
[思考] 延伸问题
- 如何平衡初始大词表的覆盖范围和计算复杂度?
- ULM是否适用于多语言场景?如何处理不同语言间的差异?
- 能否结合深度学习模型进一步优化ULM的分词效果?
来源:本文基于Unigram语言模型(ULM)的技术文档整理与总结,原文详述了ULM在自然语言处理中的应用与实现细节。