数据生产合成与质量过滤
分类:数据科学
标签:数据合成、质量过滤、模型训练
日期:2023年10月25日
数据生产合成
数据生产合成的核心在于通过多样化的 prompt(提示)设计来满足大模型在不同专项能力上的需求。这通常通过以下几种方法实现:
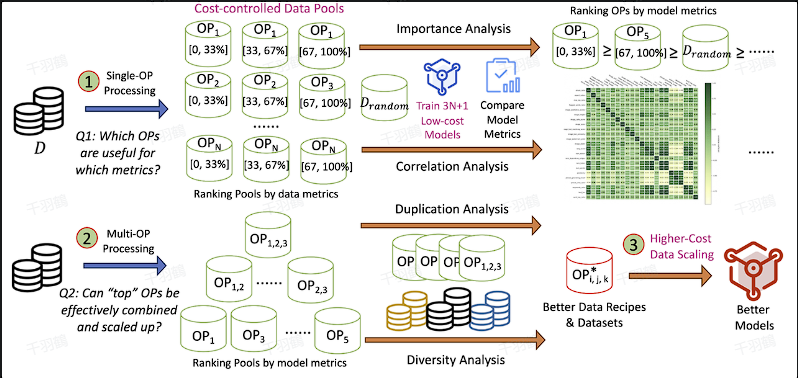
生产合成 Prompt
- Self-Instruct 方法:将技能库划分为不同的任务类型(task_type),为每个类型准备一些种子提示(seed prompt)。然后随机选择种子,利用强大模型生成更多问题。
- 启发式规则合成:通过各种启发式规则收集不同任务类型的数据集,并进行适当改写。改写可以通过强大模型完成,生成不同格式和风格的 prompt。
生产合成 Answer
使用效果好的模型如 GPT-4 来生成答案是优选方案。对于成本敏感或中文数据为主的场景,可选择在本地部署模型如 Qwen_72B。
数据质量过滤
IFD 过滤
数据质量过滤的关键在于根据指令跟踪难度筛选数据。初步训练阶段,模型通过内在的指令辨别能力评估数据集质量。
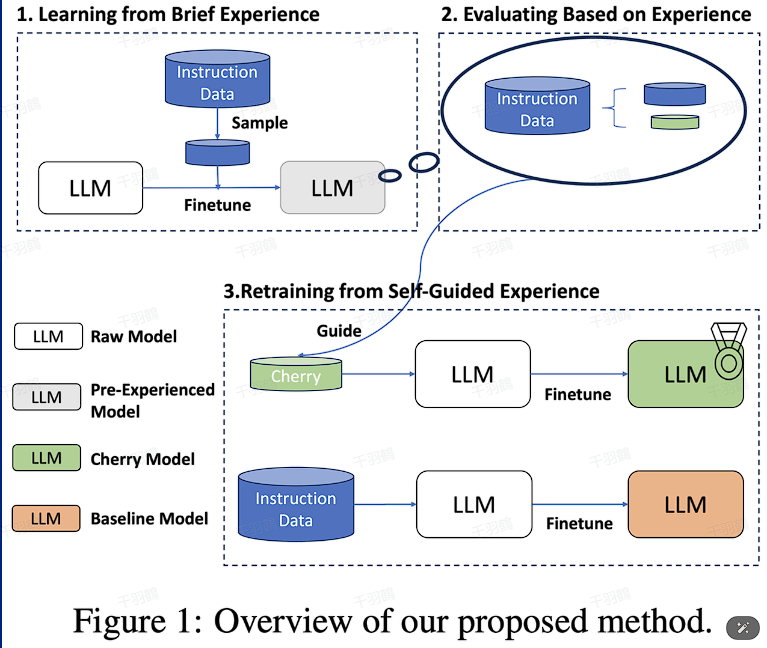
总体流程
- 经验学习:从简单经验中学习,强迫模型首先熟悉目标数据集的一个子集。
- 多样性确保:在指令嵌入上使用 K-Means 聚类方法,确保初始模型遇到足够多样的指令。
思考
- 如何在数据合成过程中更高效地提高 prompt 的多样性?
- 在数据质量过滤中,如何自动化评估指令执行难度?
- 是否有其他更有效的方法来优化小模型的训练过程?
原始出处:https://github.com/vndee/llm-sandbox、https://arxiv.org/abs/2410.23074
操作步骤
- ✅ 划分技能库并准备种子提示。
- ⚠ 使用启发式规则收集和改写数据。
- ❗ 使用强大模型生成答案并进行模型训练。
常见错误
警告:在数据合成过程中,忽视多样性可能导致模型过拟合。
💡 启发点
- 利用强大模型进行数据合成可以显著提升生成效果。
- 数据质量过滤通过指令辨别能力提高整体数据集质量。
行动清单
- 研究更多启发式规则以优化 prompt 合成。
- 探索自动化评估指令执行难度的方法。
- 试验不同模型组合以优化训练效果。
📈 趋势预测
未来,随着大模型需求的增加,数据合成和质量过滤技术将会更加智能化和自动化,以支持更复杂的任务类型。
后续追踪
- 进一步探索自我指导的方式来评估指令难度。
- 开发更高效的数据质量过滤算法。