训练技巧和训练策略
如何优化大模型训练:策略与技巧
分类:机器学习,人工智能
标签:大模型训练,多任务学习,SFT策略
日期:2023年10月20日
训练技巧
在进行大模型训练时,不同的任务类型(task_type)需要使用不同的损失函数(channel_loss)进行观察。特殊标记(special_token)的损失一开始可能会较高,但下降速度也很快。对于创作类任务,其损失通常比其他任务更高,因为这些任务的答案较为固定,搜索结果越单一,损失越低。
关键步骤
- 观察损失函数变化:✅ 不同任务需要不同的损失函数。
- 注意初始损失水平:⚠ 确保使用通用的数据进行采样,初始损失不会特别高。
- 监控损失趋势:❗ 如果损失持续升高,检查训练代码而非数据难度。
常见错误
在训练过程中,如果发现损失持续升高,不要怀疑数据的难度,而是检查训练代码是否有问题。
SFT阶段的Packing策略
在SFT(Supervised Fine-Tuning)阶段,不建议使用packing策略,因为这可能削弱模型对短查询和短答案的拟合能力。无packing情况下,短文本的梯度更集中,有助于提升模型拟合能力。然而,packing策略在大批量数据上对泛化效果无损。
重点段落
- 无packing时的梯度集中性:无packing情况下,batch的梯度全是短文本的梯度,这增强了模型对短查询的拟合能力。
- packing对泛化效果的影响:在小数据量或特定困难的数据上,packing可能损害泛化效果。
训练策略
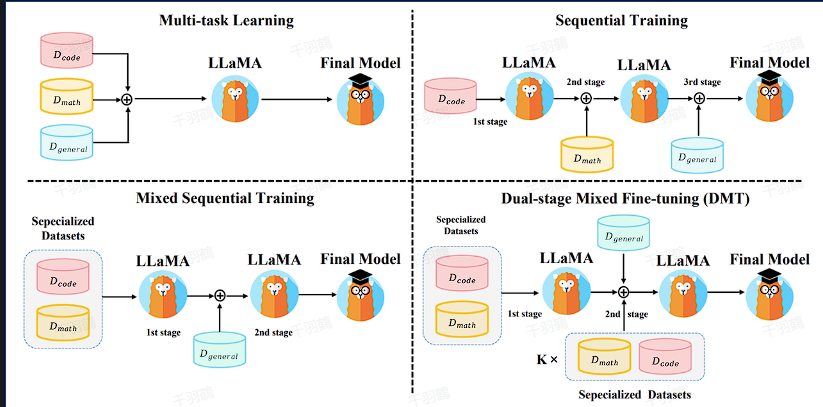
多任务学习
直接混合不同的SFT数据源并应用SFT,将每个数据源视为不同任务进行多任务学习。
顺序训练
依次在每个数据集上应用SFT,如编码、数学推理和综合能力数据集。
混合序列训练
在专业数据集(如代码、数学)上应用多任务学习,然后在通用能力数据集上应用SFT。
思考
- 在大规模数据集上,如何优化packing策略以提升泛化能力?
- 多任务学习是否适用于所有类型的数据集?
- 如何在训练过程中实时监控和调整损失函数?
来源:《Do We Really Need Packing in LLM SFT?》,《Enhancing Training Efficiency Using Packing with Flash Attention》
行动清单
📈趋势预测
随着大模型训练技术的发展,未来可能会出现更加智能的自动化调参工具,以优化训练效率和效果。
后续追踪
- 进一步研究如何在不同的数据集上优化多任务学习策略。
- 探索更多关于SFT packing策略对模型性能影响的实验证据。