激活函数与FFN结构优化:SwiGLU、GeGLU及其应用解析
激活函数与FFN结构优化:SwiGLU、GeGLU及其应用解析
元数据
- 分类:深度学习
- 标签:激活函数、FFN结构、SwiGLU、GeLU、神经网络优化
- 日期:2025年3月2日
核心内容概述
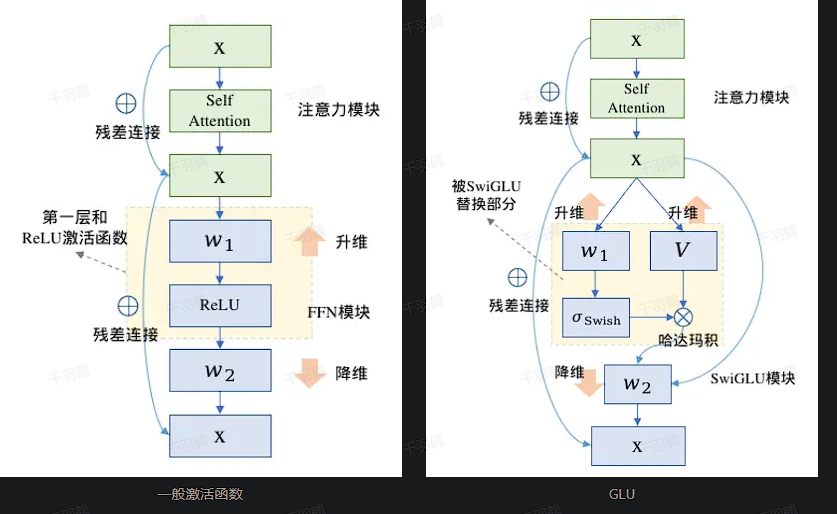
在现代大规模语言模型(如LLaMA2-7B)中,传统的前馈神经网络(FFN)结构正逐渐被更高效的变种所取代,例如SwiGLU和GeGLU。这些变种通过引入更复杂的激活函数(如Swish和GeLU),优化了计算效率和模型性能,并通过调整中间层维度来保持参数量的平衡。
关键内容解析
1. FFN结构与激活函数基础
传统FFN模块的计算公式为:
FFN(x) = ReLU(xW₁ + b₁)W₂ + b₂
- FFN的作用:处理输入特征并生成非线性输出。
- ReLU激活函数:简单但高效,通常作为FFN的默认激活函数。
2. GLU与其变种(SwiGLU、GeGLU)的改进
💡 线性门控单元(GLU):
GLU(x) = (xV) ⋅ σ(xW + b)
- 引入门控机制,通过
sigmoid选择哪些信号通过,哪些被抑制。
💡 SwiGLU 和 GeGLU 的创新:
- 将GLU中的
sigmoid替换为更复杂的激活函数:- SwiGLU:使用Swish激活函数。
- GeGLU:使用GeLU激活函数。
| 激活函数 | 公式 | 特点 |
|---|---|---|
| Swish | Swish(x) = x × sigmoid(β * x) |
平滑且具备非线性增强能力。 |
| GeLU | GeLU(x) ≈ 0.5x(1 + tanh(√(2/π)(x + 0.044715x³))) |
更适合深层网络,计算更复杂。 |
3. LLaMA2中的参数优化
📈 为了适配SwiGLU带来的额外计算开销,大模型通常对FFN的中间层维度进行调整。例如:
- LLaMA2-7B模型:
- 原始输入维度:4096。
- 中间层维度(传统FFN):4倍输入维度,即16384。
- 中间层维度(SwiGLU优化后):缩减为原来的2/3,约10922。
- 为满足256的整数倍需求,最终调整为11008。
这种调整在保持模型参数量基本不变的同时,提高了计算效率和性能。
4. 常见错误与注意事项
⚠ 常见错误:
- 忽略中间层维度调整,导致模型参数量增加过多。
- 在实现SwiGLU或GeGLU时未正确替换激活函数,影响模型性能。
- 对Swish或GeLU公式误解,导致梯度计算不准确。
代码示例
以下是一个实现SwiGLU的简单代码片段(PyTorch):
import torch
import torch.nn as nn
class SwiGLU(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(SwiGLU, self).__init__()
self.linear1 = nn.Linear(input_dim, hidden_dim)
self.linear2 = nn.Linear(hidden_dim, input_dim)
self.swish = lambda x: x * torch.sigmoid(x)
def forward(self, x):
hidden = self.swish(self.linear1(x))
return self.linear2(hidden)
# 示例
input_tensor = torch.randn(1, 4096)
model = SwiGLU(4096, 11008)
output = model(input_tensor)
print(output.shape) # 输出张量形状
个人见解 [思考]
-
激活函数选择对模型性能影响有多大?
- 为什么SwiGLU和GeLU在大模型中表现更优?是否存在其他潜在替代品?
-
参数量平衡与性能优化的权衡
- 中间层维度缩减是否会影响模型的泛化能力?是否可以通过其他方式优化?
-
未来趋势
- 📈 随着硬件性能提升,是否会有更多复杂激活函数被引入?如何评估其实际收益?
行动清单
✅ 学习并实现SwiGLU和GeGLU的代码实现。
✅ 比较不同激活函数对模型训练速度和性能的影响。
✅ 调研其他激活函数(如Mish、ELU)在大模型中的应用潜力。
后续追踪研究计划
-
深入分析:
- 对比不同激活函数在Transformer架构中的表现。
- 探索更多高效的FFN结构替代方案。
-
实验验证:
- 在中小规模数据集上测试SwiGLU和GeGLU,评估其适用性。
-
硬件适配:
- 研究新型硬件(如TPUs)对复杂激活函数的支持情况。
本文参考自深度学习相关资料与大语言模型技术文档。