旋转位置编码与ALiBi:深度学习中的位置嵌入优化
- 分类:深度学习
- 标签:位置编码,RoPE,ALiBi,Transformer
- 日期:2025年3月5日
概述
在深度学习中,位置编码是Transformer模型中不可或缺的一部分,用于引入序列的位置信息。本文介绍了两种先进的技术:旋转式位置编码(RoPE)和ALiBi(Attention Linear Bias),它们在不同场景下优化了位置嵌入的表现。
核心内容
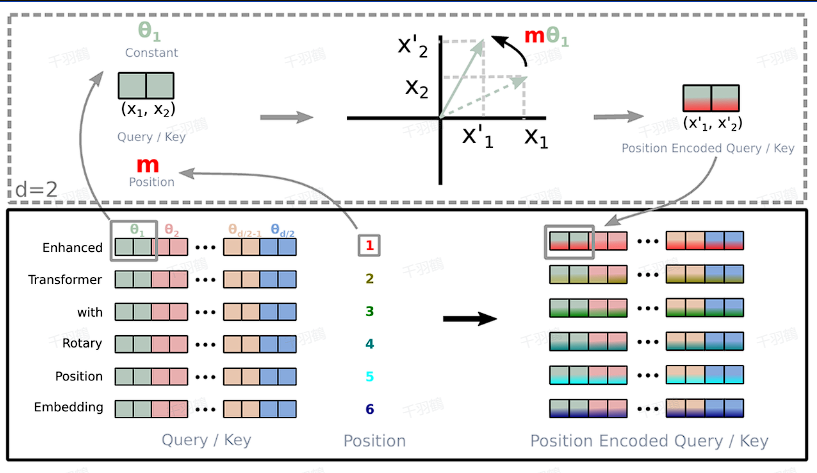
1. 什么是RoPE?
RoPE(Rotary Position Embedding)通过绝对位置编码的方式实现了相对位置编码,同时结合了两者的优点。其步骤如下:
✅ 核心原理:
- RoPE将位置信息注入到Attention机制中的查询向量 $$q$$ 和键向量 $$k$$ 中。
- 对 $$q$$ 和 $$k$$ 应用旋转变换后计算点积,从而引入相对位置信息。
✅ 二维情况下的公式:
RoPE的核心公式为:
其中,$$m$$ 是位置信息,$$\theta$$ 是旋转角度。
✅ 高维扩展:
对于偶数维向量,RoPE可以通过二维拼接扩展到高维空间。
💡 启发点:
由于旋转矩阵 $$R_m$$ 是正交矩阵,不改变向量模长,因此RoPE不会破坏模型的稳定性。
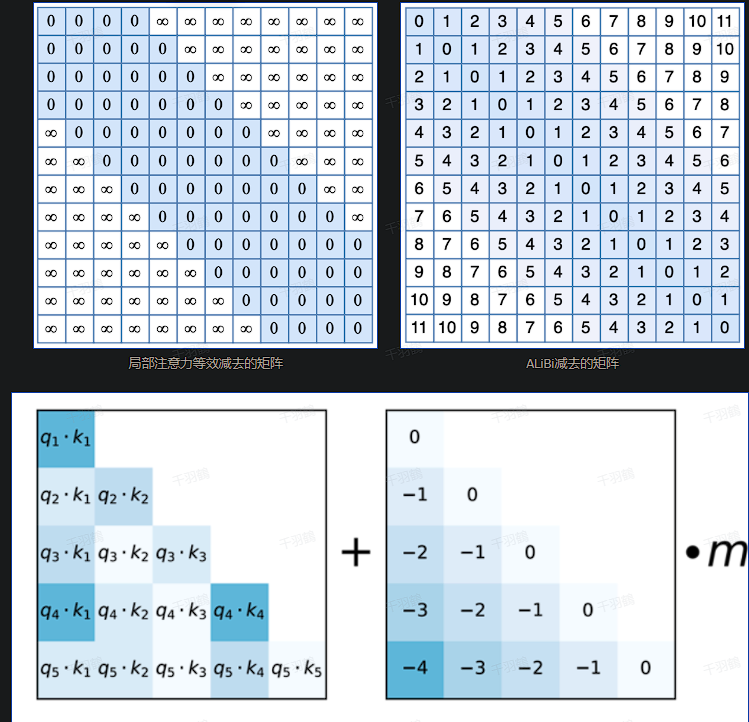
2. 什么是ALiBi?
ALiBi(Attention Linear Bias)是一种更简单的改进方法,通过在Softmax之前对Attention分数进行线性偏置调整来引入位置信息。
✅ 公式表达:
将原始Attention计算:
修改为:
其中:
💡 启发点:
ALiBi的设计类似于局部注意力机制,但它通过简单的线性偏置实现了更高效的相对位置编码。
3. RoPE与ALiBi的对比
| 特性 | RoPE | ALiBi |
|---|---|---|
| 实现方式 | 通过旋转矩阵引入相对位置信息 | 在Softmax前添加线性偏置 |
| 复杂度 | 较高 | 较低 |
| 模型稳定性 | 不改变向量模长,稳定性较好 | 简单易用,但需要调整超参数 |
| 应用场景 | 高维向量嵌入 | 长序列任务 |
常见错误
⚠ 矩阵维度匹配问题:在实现RoPE时,需确保旋转矩阵与输入向量维度一致,否则会导致计算错误。
⚠ 超参数选择:对于ALiBi,选择不合适的 $$\lambda$$ 值可能导致模型无法有效学习。
思考
- RoPE和ALiBi是否可以结合使用,以同时提升模型效率和性能?
- ALiBi是否适用于所有类型的Transformer模型,尤其是多模态任务?
- 对于长序列任务,这两种方法在性能上的差异如何?
原文出处:[选自深度学习技术文档]
行动清单
- 实现一个简单的RoPE和ALiBi代码示例,测试其效果。
- 在长文本生成任务中对比两种方法的表现。
- 探索RoPE应用于非Transformer架构(如RNN)的可能性。
后续追踪
📈 趋势预测:随着Transformer模型在大规模预训练中的广泛应用,RoPE和ALiBi可能会进一步优化以适配超长序列任务。
🔍 研究计划:尝试在多模态模型(如CLIP)中引入RoPE或ALiBi,观察其对图像和文本融合效果的影响。