数据多样性与模型优化探索
分类: 数据科学
标签: 数据多样性、聚类算法、模型优化
日期: 2023-10-13
数据多样性的核心价值
数据多样性是大模型建设中的重要环节,涵盖任务、语义、语种及数据来源的多样性。在模型预训练阶段,数据的质量和多样性直接影响模型的表现。尤其是在微调(SFT)阶段,行业普遍认为仅需高质量且多样性的少量数据(可能仅占总数据的0.5%)。通过聚类方法筛选核心样本是一种有效的解决方案。
💡 启发点:
- 数据多样性不仅提升模型泛化能力,还能减少冗余数据对训练效率的影响。
核心数据筛选方法
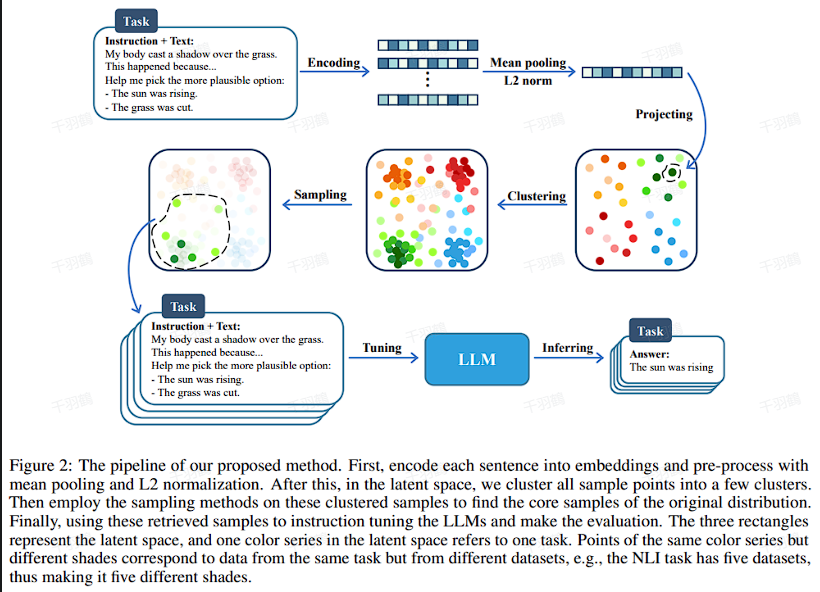
方法1:基于K-means聚类的多样性采样
✅ 步骤:
- 使用SimBERT对数据进行向量化处理。
- 通过K-means算法进行聚类。
- 从不同聚类簇中采样核心样本。
⚠ 缺点:
质量较差的样本可能因聚类分布而被采样。
方法2:加权采样(基于聚类簇的多样性权重和质量权重)
✅ 步骤:
- 对每个聚类簇计算权重,包括多样性权重和质量权重。
- 根据权重进行加权采样。
⚠ 缺点:
部分簇间样本相似度可能高于簇内样本,影响采样效果。
方法3:基于KNN聚类的权重采样
✅ 步骤:
- 计算类内平均样本相似度并反向作为多样性权重。
- 结合质量权重,最终进行加权采样。
💡 创新点:
此方法通过对比阈值相似度(如80%以内)计算权重,使得采样分布更接近正态分布。
垂域数据扩充流程
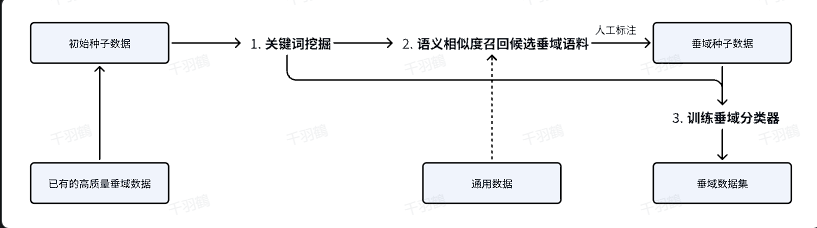
以下是从通用数据中筛选垂域相关内容的具体步骤:
数据处理与筛选流程
❗ 操作步骤:
- 初始数据爬取: 爬取尽可能多的互联网开源书籍、百科数据及网页资料,形成种子数据语料库。
- 关键词筛选: 使用jieba分词工具对种子文本进行关键词挖掘,并人工整理关键词表。
- 召回相似数据: 从通用数据中筛选出与种子数据相似度最高的前10条内容(基于前512 tokens计算相似度)。
- 人工筛选: 对召回数据进行人工标注,选择垂域相关内容作为扩充数据。
💡 启发点:
- 结合自动化工具和人工筛选,提高垂域数据的精准度。
常见错误与注意事项
⚠ 警告区块:
- 聚类算法易受噪声数据影响,需提前清洗数据。
- 类间高相似度可能导致采样结果偏差,应优化权重计算方法。
📈 未来趋势预测
随着大模型的发展,对高质量、多样性数据的需求将持续增长。未来可能会出现更加智能化的数据筛选算法,例如结合深度学习的动态聚类方法,以进一步提高效率和准确性。
思考板块
- 如何进一步优化聚类算法以减少噪声影响?
- 是否可以引入主动学习机制来动态调整采样权重?
- 在跨语种数据处理中,如何解决语义偏差问题?
来源: LIMA: Less Is More for Alignment;D4: Improving LLM Pretraining via Document De-Duplication and Diversification;DeepseekMath实践经验
行动清单
后续追踪计划
- 深入研究加权采样方法对模型微调效果的提升。
- 开发中文领域分类器并评估其准确率。
- 设计跨语种数据筛选方案,验证其在多语言模型中的适用性。