混合精度训练
分类:深度学习优化
标签:混合精度训练、梯度下溢、FP16、FP32、模型训练
日期:2023年10月30日
什么是混合精度训练?
混合精度训练是一种在深度学习中提高计算效率和降低显存占用的技术。它通过结合不同的数值精度(如 FP16 和 FP32)进行模型训练,既能减少资源消耗,又能保持模型的高精度。
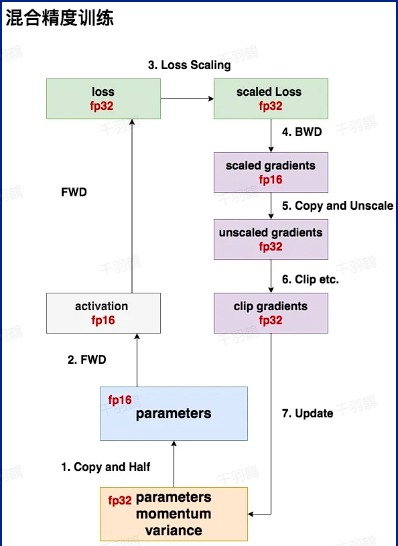
混合精度训练的核心流程
以下是混合精度训练的主要步骤:
✅ 计算准备
- 存储一份 FP32 的参数(parameter),作为主权重;同时生成一份 FP16 精度的权重,用于实际训练。
✅ 前向传播(FWD)
- 使用 FP16 的权重进行前向计算,生成 FP16 的激活值(activation);计算出的损失值(loss)以 FP32 表示,确保梯度计算准确性。
✅ 损失缩放(Loss Scale)
- 为防止梯度下溢,对损失值进行缩放处理,得到 FP32 精度的缩放损失(scaled loss)。
✅ 反向传播(BWD)
- 使用缩放后的损失计算梯度,存储为 FP16 格式的缩放梯度(scaled gradients)。
⚠ 梯度去缩放与裁剪
- 在更新权重时,将梯度转为 FP32 格式,并执行梯度裁剪操作,避免梯度爆炸或消失问题。
混合精度训练的优势
- 显存优化:通过使用 FP16,显著减少显存占用,使得更大规模的模型可以在有限硬件上运行。
- 加速计算:FP16 运算速度更快,尤其在支持 Tensor Core 的硬件上。
- 保持精度:通过 FP32 主权重和损失缩放策略,避免因低精度导致的舍入误差和梯度下溢。
常见问题与解决方法
⚠ 舍入误差
- 问题:FP16 精度可能导致舍入误差累积,影响模型更新。
- 解决方案:在更新权重时,将梯度从 FP16 转回 FP32 格式进行更新。

⚠ 梯度下溢
- 问题:FP16 的数值范围下界为 $$2^{-24}$$,导致小梯度可能被舍入为零。
- 解决方案:使用损失缩放技术,将小梯度放大到可表示范围。
数据支持
| 问题类型 | 影响范围 | 解决方法 |
|---|---|---|
| 舍入误差 | 精度下降 | 使用 FP32 主权重 |
| 梯度下溢 | 67% 梯度值小于 $$2^{-24}$$ | 损失缩放 |
💡启发点
- 损失缩放是混合精度训练的核心技术,直接影响梯度计算的稳定性。
- 在硬件支持下,混合精度可以大幅提升训练效率,是未来大模型训练的重要方向。
[思考]
- 混合精度训练是否适用于所有类型的神经网络?在某些场景下是否会有局限性?
- 损失缩放策略如何动态调整?是否可以进一步优化或自动化?
- 随着硬件发展,是否有可能完全摆脱 FP32 而直接使用更高效的低精度训练?
原文内容参考:《混合精度训练》,来源于 Megatron 文档
深度学习中的显存优化与梯度处理方法
行动清单
- 学习并实现一个简单的混合精度训练模型,观察性能提升效果。
- 研究损失缩放算法的具体实现机制及其对不同任务的适配性。
- 关注最新硬件(如 NVIDIA Tensor Core)的支持情况,评估其对混合精度训练性能的影响。
📈 趋势预测
随着 AI 模型规模不断扩大,混合精度训练将成为主流方法之一,尤其是在硬件逐步优化支持低精度计算的背景下,其应用范围将进一步拓展。
后续追踪
- 深入研究自动损失缩放算法(Automatic Mixed Precision, AMP)的实现细节。
- 关注其他数值格式(如 bfloat16)的发展及其对混合精度训练的影响。