预训练的Scaling Law
预训练模型的Scaling Law及优化
分类:深度学习
标签:预训练模型,Scaling Law,计算预算,深度学习优化
日期:2023年10月XX日
核心观点总结
在深度学习模型的预训练中,资源预算、数据量和模型尺寸之间存在紧密关系。通过Scaling Law(缩放定律),可以优化计算资源的使用,确定最佳模型大小和数据集规模。
核心内容
1. 计算预算公式及其意义
计算预训练所需资源的公式为:
- 通俗解释:FLOPs(浮点运算次数)是衡量计算量的标准。公式表明,计算预算与数据规模和模型参数数成正比。
- 示例:使用100台A800显卡训练一个月,每块A800的吞吐量为210 TFLOPs:
2. 数据与模型尺寸的平衡
给定固定预算,数据量与模型尺寸成反比:
- 小模型+大数据:例如,7B(70亿参数)模型可以训练约10T Tokens。
- 大模型+小数据:例如,70B(700亿参数)模型只能训练约1T Tokens。
💡 启发点:在实际应用中,需要根据任务的需求选择“更多数据”还是“更大模型”。
3. Scaling Law实验结果
Llama3团队通过实验验证了Scaling Law:
- 在不同预算下($$6 \times 10^{18}$$到$$10^{22} FLOPs$$),调整模型大小(40M到16B参数)。
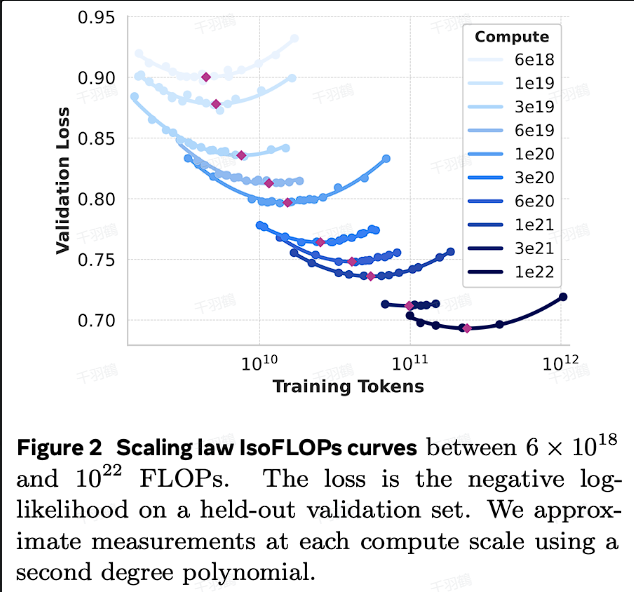
- 使用幂律公式拟合最优点:
- 忽略了预算对Token数量和模型大小的限制。
- 未根据实验数据调整模型参数,可能导致资源浪费。
操作步骤
✅ 步骤1:确定可用计算预算,例如显卡数量、每日工作时间。
✅ 步骤2:使用公式估算FLOPs预算,并选择合适的模型和数据规模平衡策略。
✅ 步骤3:参考Scaling Law实验结果,验证模型与数据组合是否接近最优点。
数据表格
| 模型大小 (参数数量) | 数据量 (Tokens) | FLOPs预算范围 ($$10^{18}$$ FLOPs) |
|---|---|---|
| 小模型 (40M) | 大量数据 | $$6 - 10$$ |
| 中等模型 (7B) | 中等数据 | $$10 - 100$$ |
| 大模型 (16B) | 少量数据 | $$100 - 1000$$ |
📈 趋势预测
未来预训练中的Scaling Law可能进一步优化:
- 自适应算法:动态调整模型与数据比例。
- 硬件优化:更高效的硬件(如H100)将降低FLOPs成本。
- 混合训练策略:结合小模型预热和大模型微调。
[思考]板块
- 如何在有限预算下进一步提升预训练效率?
- 是否可以通过迁移学习减少对大规模数据的依赖?
- Scaling Law是否适用于特定领域(如医学、金融)的定制模型?
原文出处:Llama3 Scaling Law
行动清单
后续追踪
- 收集更多实验数据验证Scaling Law在大规模项目中的适用性。
- 探讨如何利用多模态数据进一步优化预训练。