预训练策略
元数据
- 分类:深度学习
- 标签:预训练策略,学习率调度,模型优化
- 日期:2023年10月25日
核心观点总结
在深度学习模型的预训练过程中,优化策略至关重要。本文探讨了如何通过调整 batch_size、采用 WSD调度器 和 预训练Trick 来提升模型训练效率,同时总结了四阶段预训练设置的具体流程。
重点内容
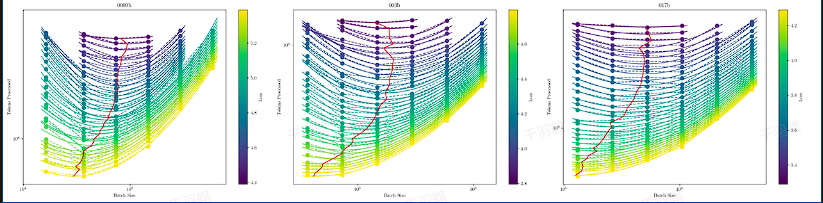
最优 Batch Size 的选择
- 关键点:Batch size 影响模型收敛速度与资源消耗的平衡。
- 数据实验表明:
- Batch size 过大,数据和计算量增加。
- Batch size 过小,训练步数增多且损失函数下降受限。
- C4 Loss 的规律公式:
WSD 调度器的三阶段学习率策略
- 分阶段特点:
- 快速收敛阶段(Warmup):学习率线性上升。
- 稳定阶段(Stable):保持最大学习率。
- 退火阶段(Decay):采用余弦退火算法逐步降低学习率。
- 学习率公式:
-
提高效率的预训练技巧
- 显存优化:
- 若显存充足,尽量避免引入复杂并行技术(如 tensor_parallel)。
- 不开启 offload 和 重算 可节省时间。
- 指令数据:
- 加入更多指令数据有助于提升模型性能。
✅ 四阶段预训练设置流程
- Warmup 阶段:
- 学习率缓慢上升到最大值。
- 中期稳定阶段:
- 使用较大的学习率,是否引入衰减需视实验而定。
- 后期适应阶段:
- 改变 RoPE 的 base 频率,增加文本长度,让模型适应长文本任务。
- 收尾退火阶段:
- 使用高质量数据(如 IFT 数据)强化模型能力,为 benchmark 测试做准备。
⚠ 常见错误与注意事项
警告区块
- 忽视 batch size 对训练效率的影响,可能导致资源浪费或性能不足。
- 在显存不足时强行引入复杂并行技术,可能引发调试困难和性能下降。
📈 趋势预测
未来预训练策略可能会更加注重以下方向:
- 自动化调参工具的普及,减少人工调整成本。
- 更智能的数据采样方法,提升高质量数据使用比例。
- 多模型协同训练策略(如多任务联合训练)的进一步发展。
[思考] 延伸问题
- 如何在不同硬件条件下灵活调整 batch size 和学习率?
- 是否存在更高效的调度器替代 WSD 调度器?
- 长文本适应性优化是否能迁移至多模态任务中?
原文出处:深度学习预训练策略文档