ReMax
ReMax: Reinforcement Learning for Large Language Models
分类
自动推断
标签
- 强化学习
- 策略梯度
- PPO算法
- 大型语言模型
日期
2025年4月12日
内容摘要
ReMax是一种简单、有效且高效的强化学习方法,旨在对齐大型语言模型。本文回顾了策略梯度与PPO算法的基本概念,并介绍了如何通过优势函数指导策略更新。
策略梯度与PPO回顾
策略梯度方法通过奖励估计值
当计算期望时,基于多条样本的公式为:
重点段落
- 轨迹的总回报:通过累积折扣奖励来估计
。 - 蒙特卡洛估计:提供动作后的回报,但方差较大。
- 基线改进版本:通过加入基线
降低方差,常用基线是价值函数 。
PPO算法简化
PPO算法利用优势函数指导策略更新,通过剪辑机制来稳定训练过程。其核心思想简化为:
操作步骤
- ✅ 使用轨迹的总回报进行初步估计。
- ⚠ 选择合适的基线以降低方差。
- ❗ 实施PPO剪辑机制以稳定训练。
常见错误
注意:蒙特卡洛估计可能导致方差过大,需谨慎使用。
💡启发点
PPO算法通过剪辑机制有效地稳定了策略更新过程,值得在其他强化学习应用中借鉴。
行动清单
- 探索其他基线选择对策略梯度方法的影响。
- 实验不同剪辑参数对PPO算法性能的影响。
- 应用ReMax方法于其他大型语言模型。
ReMax具体算法
元数据
- 分类:机器学习
- 标签:ReMax,策略梯度,强化学习,算法
- 日期:2025年4月12日
核心观点总结
ReMax算法是基于策略梯度方法的强化学习算法,旨在通过修改基线计算来降低方差。它结合了REINFORCE方法和最大化策略,特别适用于大模型强化学习场景。
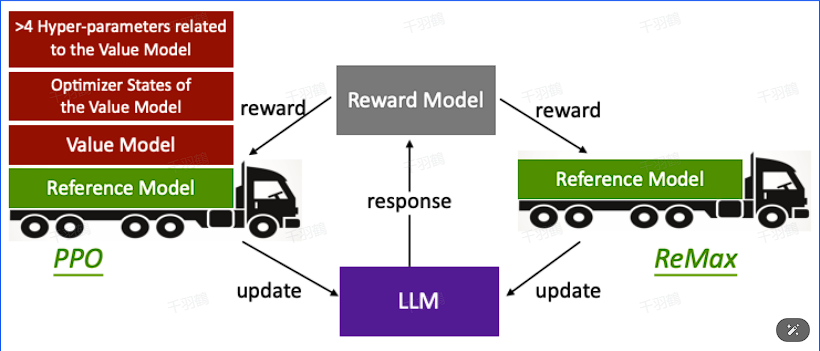
重点段落
ReMax的基本概念
ReMax算法的出发点是去掉Critic Model,类似于GRPO,它在策略梯度的基础上进行改进。ReMax完全回到了策略梯度算法,并对其中的基线计算进行了修改。
REINFORCE方法的修正
在REINFORCE中,传统上使用蒙特卡洛方法估计回报,但这会导致高方差。在大模型强化学习中,只有最后一个动作处有奖励,因此中间的奖励被视为0,这样修正后的形式可以更好地适应大模型场景。
基线计算的创新
ReMax通过减去基线值来降低方差。基线值是通过每个输出token处使用贪心解码产生的响应的奖励值计算得出的。这种方法有效减少了方差。
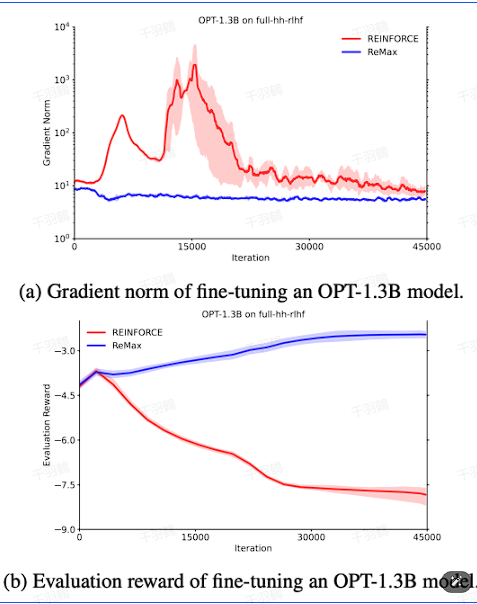
操作步骤
- ✅ 从策略梯度中的REINFORCE方法出发,使用蒙特卡洛估计后续回报。
- ⚠️ 考虑到大模型强化学习中只有最后一个动作处有奖励,中间动作处的奖励视为0。
- ❗ 使用贪心解码产生的响应奖励值作为基线值来降低方差。
常见错误
⚠️ 注意:在使用REINFORCE方法时,直接使用蒙特卡洛估计可能导致方差过大,需通过基线值调整来解决。
💡 启发点
- ReMax算法通过创新的基线计算方法,有效解决了传统REINFORCE方法中的高方差问题,为大模型强化学习提供了新的思路。
行动清单
- 研究ReMax算法在不同大模型上的应用效果。
- 探讨其他可能的基线计算方法。
- 实现ReMax算法并与其他强化学习算法进行对比实验。
数据转换
| 参数 | 描述 |
|---|---|
| 策略梯度 | |
| 奖励函数 | |
| 基线值 |
公式显示
来源:本文内容参考了相关技术文档与研究论文,具体出处请参阅相关文献。