强化学习分类
强化学习分类与策略优化
元数据
- 分类:人工智能
- 标签:强化学习, 策略优化, 数据采样, 环境动态
- 日期:2025年4月11日
内容概要
在强化学习领域中,策略优化的分类是一个重要的研究方向。本文将讨论几种主要的分类概念,包括在线与离线学习、策略采样与更新、环境动态的需求以及策略学习的方法。
以数据来源划分
-
Online:代理(Agent)在与环境交互时,实时收集轨迹样本并进行策略学习。这样的过程可以用以下形式表示:
代理一边收集数据,一边更新其策略。
-
Offline:代理使用预先收集好的轨迹样本进行学习,这些样本作为一个离线数据集提供给代理,学习过程中不涉及环境交互。
以采样策略和更新策略划分
-
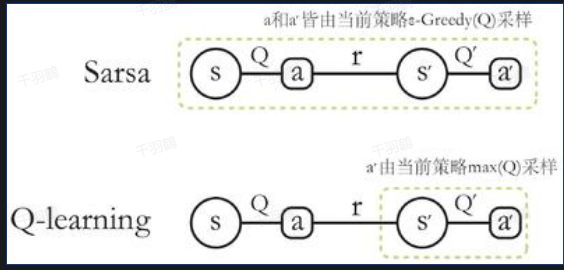
On-Policy:采样的行为策略和更新的目标策略是同一个策略。例如,SARSA算法在更新时需要使用当前行为策略采样得到的五元组数据:
-
Off-Policy:采样的行为策略和更新的目标策略不是同一个策略。例如,Q-learning算法使用当前行为策略采样的四元组:
而
是通过 得到的,而不是行为策略采样得到的。
以需不需要环境动态划分
-
Model-based:环境动态已知或通过学习得到环境模型,通过动态规划或树搜索等方法直接求解最优策略,代理无需与环境交互采样。
-
Model-free:环境动态未知,通过代理与环境交互采样来学习策略,而不需要学习状态转移模型。
以如何学习策略划分
-
Value-based:先学习值函数,然后从值函数导出策略,过程中不存在显式的策略。
-
Policy-based:直接显式地学习一个目标策略。
常见错误
在使用Off-Policy方法时,需注意行为策略与目标策略的区别,否则可能导致错误的策略更新。
💡启发点
通过不同的分类方法,可以灵活地选择适合具体问题的强化学习算法,提升策略优化效率。
行动清单
- 探索如何结合Online和Offline方法以提高数据利用率。
- 实验不同的Model-based与Model-free方法在特定任务中的性能表现。
- 对比Value-based与Policy-based方法在复杂环境中的适用性。
📈趋势预测
随着计算能力和算法研究的深入,强化学习中Model-free方法可能会在更多领域得到应用,尤其是在复杂环境中。
后续追踪
- 探索如何将不同策略优化方法结合,以应对多变环境。
- 研究如何动态调整行为和目标策略,以提高适应性。
来源:本文内容基于强化学习分类及策略优化相关资料编写。