强化学习问题,流程
强化学习基础:序贯决策与智能体交互
分类:机器学习
标签:强化学习, 序贯决策, 智能体, 奖励机制
日期:2025年4月7日
强化学习问题与流程
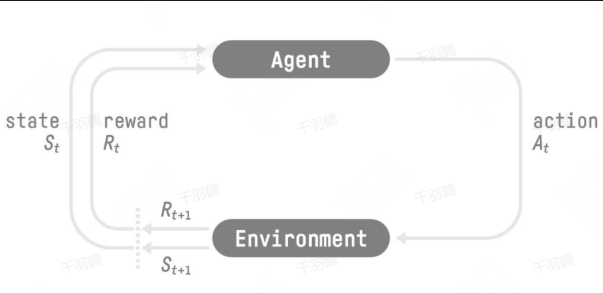
强化学习是一种机器学习方法,旨在通过与环境的交互来学习最优的行为策略,以解决需要序贯决策的问题。序贯决策类似于人生中的重要选择,因其决策会带来后果,需要在未来时间点做出进一步决策。这种方法的核心思想是通过试错(Trial and Error)和奖励机制指导智能体(Agent),以最大化长期累积奖励。
应用场景
- 控制问题
- 游戏
- 资源管理优化
- 金融风险控制
- 推荐算法
强化学习的流程
强化学习通过以下步骤实现目标:
- ✅ 感知环境状态:智能体感知当前环境状态。
- ⚠ 动作决策:基于所感知的状态,智能体计算并选择一个动作。
- ❗ 环境反馈:动作作用于环境,环境发生变化并反馈即时奖励及新状态。
- ✅ 更新策略:智能体根据奖励调整策略,以在未来获得更高的累积奖励。
这种交互是迭代进行的,目标是最大化多轮交互中累积奖励的期望。
常见错误
警告:在实现强化学习时,可能会过于依赖即时奖励而忽略长期策略优化,导致局部最优而非全局最优。
💡 启发点
强化学习强调智能体不仅能感知环境,还能通过决策直接改变环境,这与传统有监督学习中的模型有本质区别。
📈 趋势预测
随着大模型的兴起,LLM-based agent 将可能在强化学习中发挥更大的作用,尤其是在复杂环境下的决策优化。
[思考]板块
- 在强化学习中,如何更有效地平衡探索与利用?
- LLM-based agent 在复杂决策环境中有哪些优势?
- 如何在实际应用中提升强化学习算法的效率?
原始出处:动手学强化学习
行动清单
- 研究不同类型的奖励机制对策略优化的影响。
- 探索 LLM-based agent 在具体应用中的潜力。
- 设计实验验证不同神经网络结构在强化学习中的表现。
后续追踪
- 持续关注 LLM 在强化学习领域的新进展。
- 探索多智能体系统中的协作策略优化。