马尔可夫决策过程
马尔可夫决策过程与策略价值分析 | 强化学习基础
分类:自动推断
标签:马尔可夫决策过程, 强化学习, 策略价值
日期:2025年4月7日
🚀 核心观点
马尔可夫决策过程(MDP)是强化学习中用于抽象实际问题的基础结构。MDP由五元组 $$(S, A, P, r, \gamma)$$ 构成,其中包含状态集合、动作集合、状态转移函数、即时奖励函数和折扣因子。策略(Policy)是智能体在不同状态下采取动作的概率分布,分为确定性策略和随机性策略。状态价值函数和动作价值函数用于衡量策略的优劣。
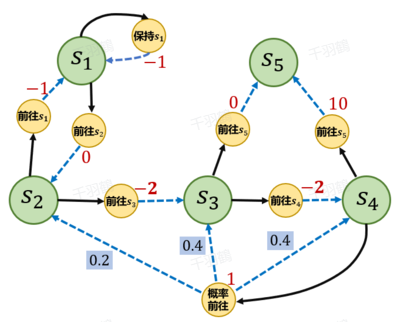
📊 重点段落
状态价值函数
状态价值函数 $$V_\pi(s)$$ 表示在状态 $$s$$ 下,遵循策略 $$\pi$$ 的期望收益。公式为:
动作价值函数
动作价值函数 $$Q_\pi(s, a)$$ 表示在状态 $$s$$ 下执行动作 $$a$$ 时的期望回报:
策略与价值函数的关系
状态价值函数与动作价值函数的关系如下:
✅ 操作步骤
- 定义问题:将实际问题抽象为MDP。
- 选择策略:根据问题选择合适的策略(确定性或随机性)。
- 计算价值函数:使用状态或动作价值函数评估策略。
- 优化策略:调整策略以最大化期望回报。
⚠ 常见错误
- 忽视折扣因子 $$\gamma$$ 对长期收益的影响。
- 在随机性策略中误解概率分布的意义。
💡 启发点
- 确定性策略和随机性策略的选择对强化学习结果有何影响?
- 如何在复杂环境中有效计算状态和动作价值?
📈 趋势预测
随着计算能力的提升,强化学习在自动驾驶、金融预测等领域将得到更广泛应用,MDP模型将更为复杂和精确。
[思考] 板块
- 如何在多智能体环境中应用MDP?
- 在动态环境中,如何实时调整策略以适应变化?
- 是否有可能开发出通用的策略优化算法?
原始出处:马尔可夫决策过程
行动清单
- 研究不同环境下的MDP建模方法。
- 实践编写简单的MDP模型以加深理解。
- 探索强化学习在新兴领域的应用潜力。
后续追踪
- 进一步研究多智能体系统中的MDP应用。
- 开发实时策略调整算法以应对动态环境。