PPO训练的trick和问题
PPO模型训练技巧与问题分析
元数据:
- 分类:机器学习
- 标签:PPO, 强化学习, Token奖励
- 日期:2025年4月12日
PPO训练中的关键技巧
在PPO模型训练中,我们会采用一些技巧来优化模型的性能。这些技术包括Token级别的KL惩罚、广义优势估计(GAE)以及加入SFT损失等。这些方法不仅能够改善模型的训练效果,还能保留SFT模型的既有能力。
Token Level KL-Penalty
KL散度用于计算RL模型与SFT模型在每个token上的响应分布差异。这个散度在训练过程中作为奖励函数中的惩罚项被纳入,具体公式如下:
其中,KL(t)的计算公式为:
💡 启发点:使用KL散度作为惩罚项可以有效控制模型偏离预训练策略的程度。
Generalized Advantage Estimation (GAE)
GAE用于估计逐个token的奖励。通常情况下,我们设置
Adding SFT Loss
在PPO训练中,我们可以加入额外的监督下一个token预测损失,以及KL散度,这样可以保留SFT模型的既有能力。
操作步骤
- ✅ 计算每个token的KL散度并加入奖励函数。
- ⚠ 设置GAE参数以优化奖励估计。
- ❗ 在PPO中加入SFT损失以保留模型能力。
常见错误
在计算KL散度时,确保使用正确的分布比例,否则可能导致训练过程不稳定。
行动清单
- 研究如何有效设置KL散度的惩罚系数
。 - 实验不同GAE参数对模型性能的影响。
- 探索其他可能的损失函数组合以优化PPO训练。
来源:原始内容来自某技术文档或研究论文。
PPO优化与对齐税影响分析
分类
自动推断:机器学习
标签
- PPO
- 对齐税
- 强化学习
- NLP
日期
2025年4月12日
内容概述
在现代自然语言处理任务中,PPO(Proximal Policy Optimization)作为一种强化学习算法,常用于优化策略以对齐人类偏好。然而,PPO在优化过程中可能引发所谓的“对齐税”,即尽管对齐人类偏好,但可能导致模型在某些NLP基准上的性能下降。为解决这一问题,InstructGPT提出了PPO-ptx方法,通过增加预训练损失(ptx loss)来避免策略遗忘预训练阶段学习到的知识。
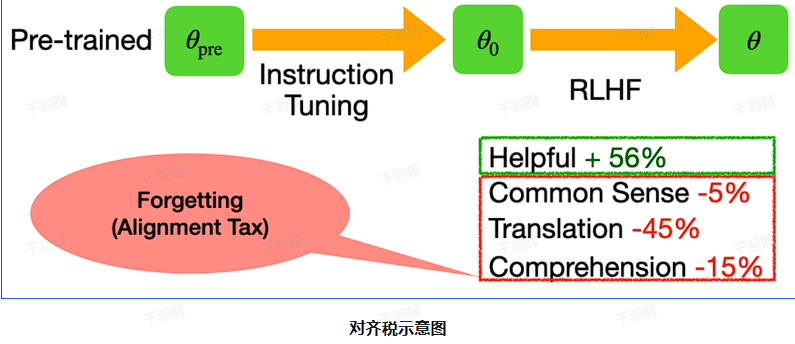
核心观点
- PPO-ptx通过在PPO优化目标中增加预训练损失,以减轻对齐税的影响。
- KL Reward的系数
的设置至关重要,需结合目标KL来确定。 - 在强化学习中,奖励归一化和优势归一化技术有助于训练稳定性。
重点段落
PPO-ptx优化目标
PPO-ptx在原有的PPO优化目标基础上增加了预训练数据集上的优化目标,以避免策略遗忘预训练阶段的知识。这种方法旨在减轻对齐税,即虽然RLHF有助于对齐人类偏好,但可能导致模型在某些NLP基准上的性能下降。
KL Reward系数设置
KL Reward中的系数

预训练损失PTX Loss
InstructGPT中将
操作步骤
- ✅ 确定PPO优化目标,包括加入预训练损失。
- ⚠ 设定KL Reward系数
,需结合目标KL进行实验。 - ❗ 调整PTX Loss系数
,确保模型收敛。
常见错误
警告:在设定KL Reward系数时,不考虑目标KL的变化可能导致策略过拟合。
💡启发点
PPO-ptx方法通过增加预训练损失有效减轻了对齐税的影响,为优化人类偏好提供了新的视角。
行动清单
- 研究更多关于对齐税的影响因素。
- 测试不同参数设置下的PPO性能。
- 探索其他可能的优化方法以进一步提高模型性能。
数据表格示例
| 参数 | 设定值 | 备注 |
|---|---|---|
| 0.001 | KL散度系数 | |
| <1 | PTX Loss系数 |
来源标注
原始出处:论文InstructGPT,Anthropic团队研究报告。
强化学习中的奖励利用与泛化问题
元数据:
- 分类:自动推断
- 标签:强化学习,奖励黑客,泛化问题,过拟合,测试集合
- 日期:2025年4月12日
核心观点
在强化学习(RL)的训练过程中,可能会出现训练集上的奖励(train reward)不断增长,但在测试集上的效果却下降的现象。这主要是由于奖励黑客(Reward hacking)和泛化问题(Generalization issue)导致的。
重点段落
-
奖励黑客问题:
当训练集上的奖励增长时,可能是因为奖励模型被“黑”了。这意味着虽然表面上看训练集的表现提高了,但实际上在人工评估时效果却下降。 -
泛化问题:
如果训练集上的人工评估结果也在上涨,那么奖励黑客没有发生。然而,如果测试集上的效果下降,这表明模型可能过拟合了训练集,导致泛化问题。 -
解决方案:
需要在模型训练过程中监控测试集的表现,确保模型不仅在训练集上表现良好,也能在未见过的数据上保持良好的性能。
操作步骤
- ✅ 确保训练过程中监控测试集的表现。
- ⚠ 注意奖励模型可能被“黑”的风险。
- ❗ 识别和处理模型的过拟合现象。
常见错误
警告:过度依赖训练集上的表现而忽视测试集的效果可能导致模型无法泛化。
💡 启发点
- 在强化学习中,不仅要关注训练集的表现,还要特别注意测试集的效果,以避免过拟合和奖励黑客问题。
行动清单
来源:本文内容基于对强化学习中奖励利用与泛化问题的分析和总结。