Actor-Model
强化学习中的PPO算法与Actor模型
元数据
- 分类:机器学习
- 标签:PPO算法, 强化学习, Actor模型
- 日期:2025年4月12日
文章内容
在这篇博客中,我们将探讨如何在强化学习中使用PPO(Proximal Policy Optimization)算法来优化Actor模型。PPO是一种用于策略优化的算法,能够在保证策略更新稳定性的同时提高学习效率。
核心观点
PPO算法通过计算策略的损失函数来更新Actor模型。具体来说,输入一条prompt(批大小为1),输出其对应的response,然后将prompt与response结合计算损失,用于更新Actor。PPO算法中的损失计算涉及到优势函数(Advantage Function),并在每个输出token处计算损失。
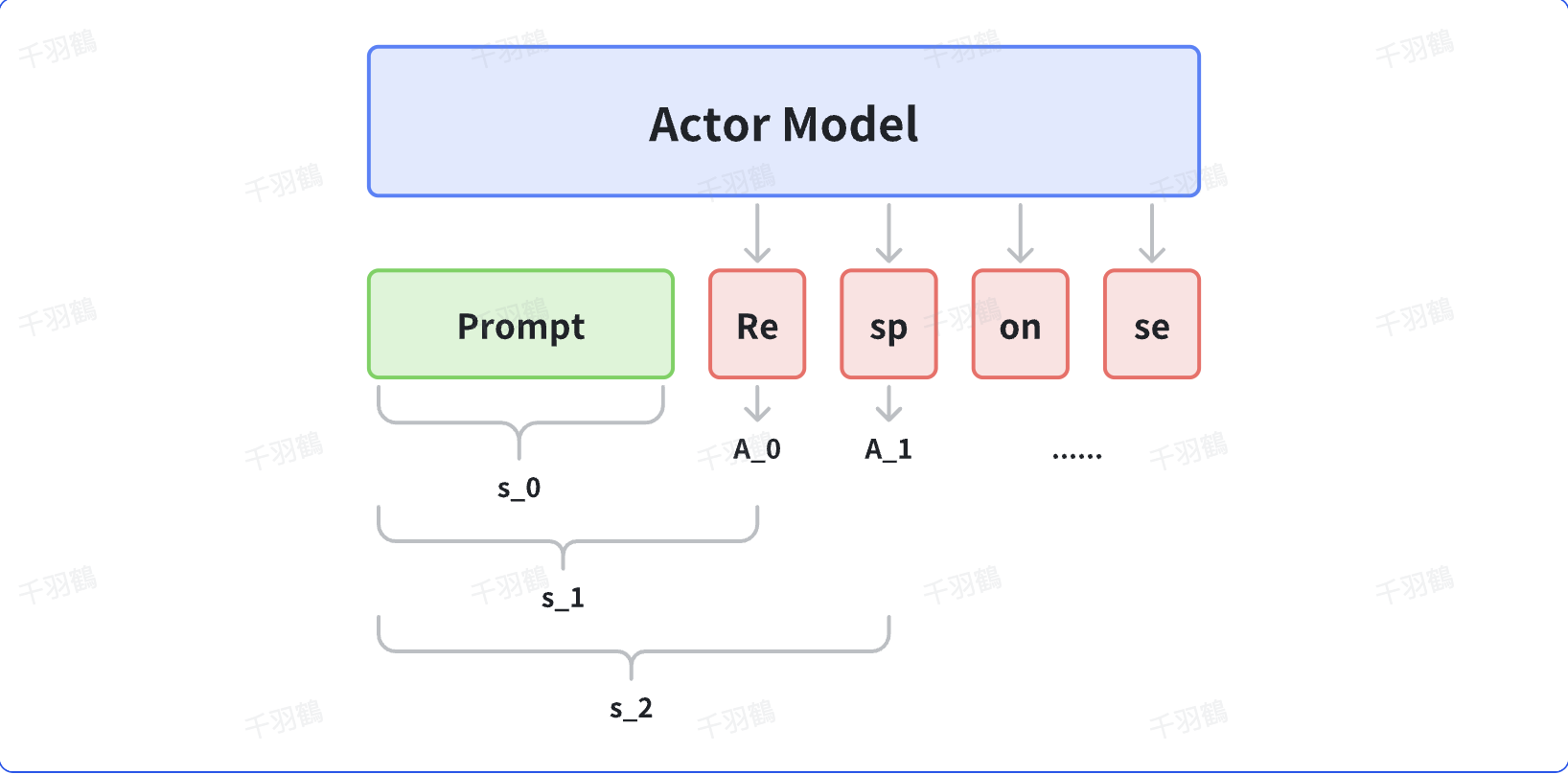
重点段落
-
损失函数的定义:
PPO算法中的Actor损失函数定义为:其中,
取0到1之间的值。 -
代码实现:
class PolicyLoss(nn.Module): """Policy Loss for PPO""" def __init__(self, clip_eps: float = 0.2) -> None: super().__init__() self.clip_eps = clip_eps def forward(self, log_probs: torch.Tensor, old_log_probs: torch.Tensor, advantages: torch.Tensor, action_mask: Optional[torch.Tensor] = None) -> torch.Tensor: ratio = (log_probs - old_log_probs).exp() surr1 = ratio * advantages surr2 = ratio.clamp(1 - self.clip_eps, 1 + self.clip_eps) * advantages loss = -torch.min(surr1, surr2) loss = masked_mean(loss, action_mask, dim=-1).mean() return loss def masked_mean(tensor, mask, dim): if mask is None: return tensor.mean(axis=dim) return (tensor * mask).sum(axis=dim) / mask.sum(axis=dim) -
优势函数的计算:
优势函数在每个输出token处都进行计算,以确保策略更新的准确性。
操作步骤
- ✅ 输入一条prompt并获取对应的response。
- ⚠ 将prompt与response结合计算损失。
- ❗ 使用PPO算法更新Actor模型。
常见错误
警告:在实现PPO算法时,需注意优势函数的准确计算,尤其是在处理不同批次数据时,可能会出现误差。
💡启发点
在实现策略优化时,使用token-level的优势函数可以提高模型的精度和稳定性。
行动清单
原文出处:本文内容基于强化学习领域的PPO算法及其应用于Actor模型的研究与实践。