Instruct-GPT
InstructGPT与人类反馈对齐技术揭秘
元数据
- 分类:人工智能、自然语言处理
- 标签:InstructGPT、RLHF、PPO、深度学习
- 日期:2025年4月12日
内容概述
InstructGPT是OpenAI在语言模型后训练中应用RLHF(人类反馈的强化学习)技术的一个重要里程碑。通过结合PPO算法,InstructGPT使得模型能够更好地与人类意图对齐。核心流程包括SFT训练、偏好标签收集、Reward Model构建以及PPO算法优化。
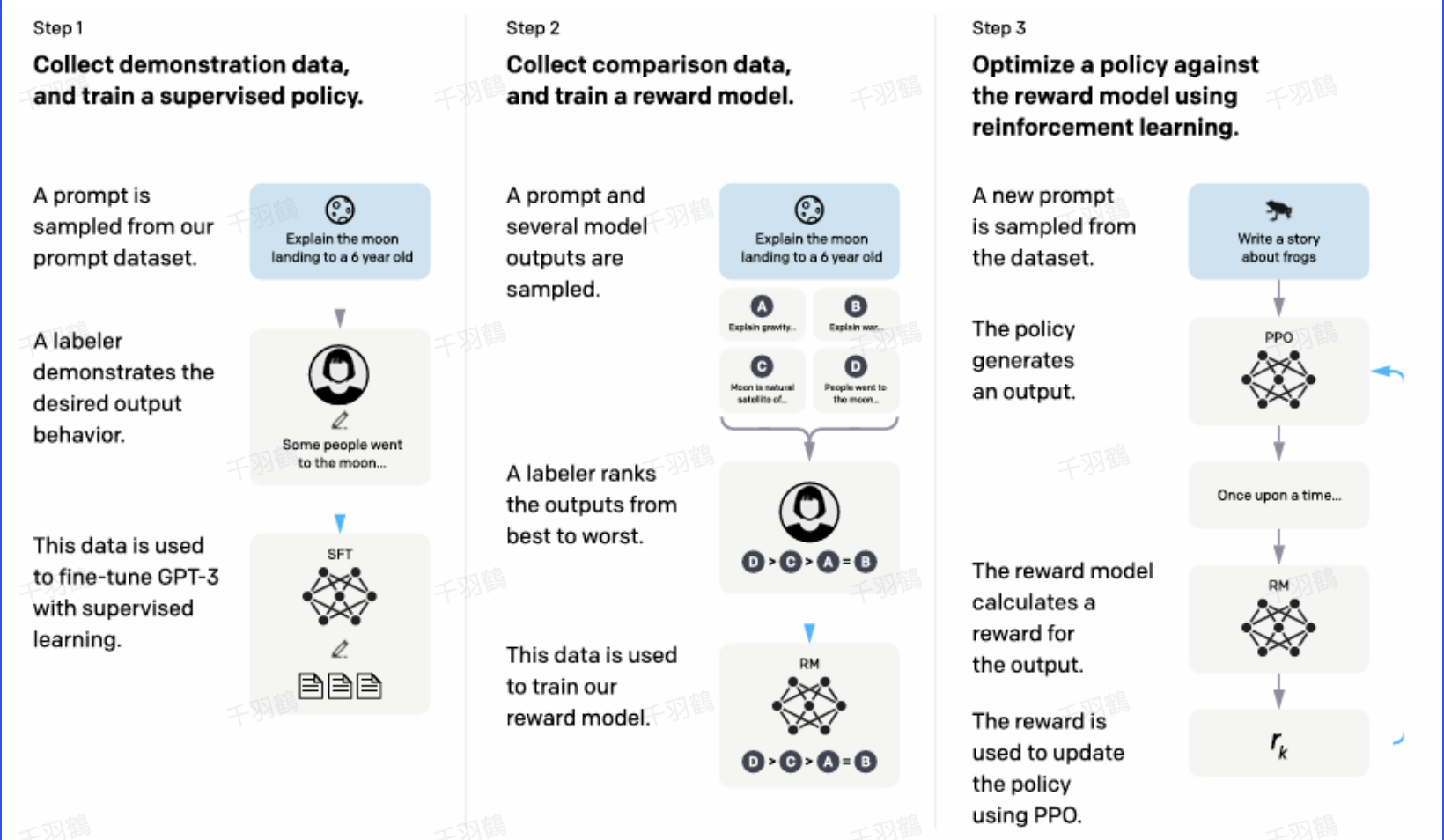
关键流程与技术
InstructGPT的训练流程
- ✅ SFT训练:基于GPT-3进行初步训练,以增强模型的指令遵循能力。
- ⚠ 人类反馈标签:人工给数据打偏好标签,收集多种回答的排序信息。
- ❗ Reward Model构建:移除SFT模型的最后非嵌入层,并增加线性层以输出标量奖励值。
- ✅ PPO算法应用:最大化Reward Model提供的奖励值进行优化,确保模型不偏离初始SFT策略。
强化学习目标修改
InstructGPT在实现PPO时修改了传统的强化学习目标,通过引入行为约束项和pretrain数据梯度,避免RL策略过度优化。
公式:
警告区块
- 常见错误:在Reward Model构建时,确保线性层的输出为标量值,以避免奖励计算错误。
💡启发点
- 引入行为约束项的奖励函数设计,为模型训练提供了更稳定的优化路径。
行动清单
- 研究如何进一步优化偏好标签收集过程。
- 探讨其他算法在RLHF中的应用潜力。
- 评估InstructGPT在不同领域指令遵循能力的表现。
后续追踪
- 探索InstructGPT在多语言环境下的适用性。
- 分析RLHF技术在其他AI模型中的应用效果。
[思考]板块
- 如何有效地评估人类偏好标签的质量?
- RLHF能否应用于其他类型的机器学习任务?
- 在多语言模型中,如何确保跨语言的一致性?
来源:OpenAI InstructGPT研究论文《Training language models to follow instructions with human feedback》链接