RL在NLP场景下的拓展
强化学习在自然语言处理中的应用:MDP建模与优化目标
- 分类:自然语言处理
- 标签:强化学习,MDP建模,自然语言处理,优化目标,行为约束
- 日期:2025年4月12日
核心观点总结
在自然语言处理(NLP)任务中应用强化学习(RL),需要进行马尔可夫决策过程(MDP)建模。通过明确定义代理、环境、状态和动作,可以实现对NLP任务的优化。强化学习的主要目标是最大化累积奖励的期望值,并通过行为约束来防止策略偏离。
重点段落
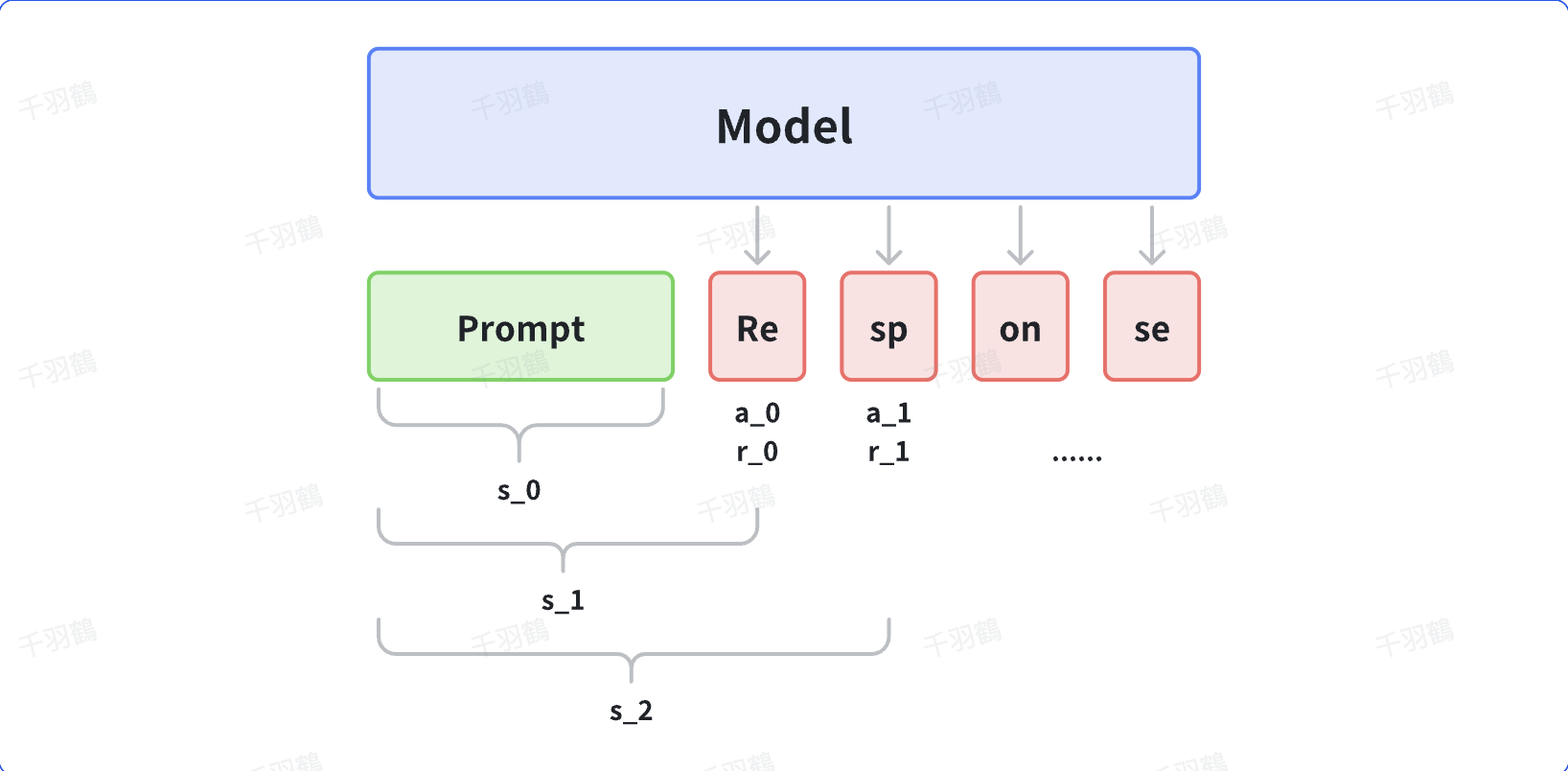
NLP MDP建模
强化学习应用于NLP任务时,需进行MDP建模。具体来说:
- 动作(
):生成的token,动作空间为整个词表。 - 策略(
):当前状态生成动作token的概率。 - 状态(
):上文及当前时刻前生成的所有token序列,初始状态为prompt的token序列。 - 状态转移:通过当前状态和动作的token序列确定下一个状态。
强化学习优化目标
强化学习旨在最大化累积奖励的期望值:
其中
行为约束优化目标
带行为约束的优化目标通过修改奖励值来限制策略更新:
目的是约束策略在距离行为/参考策略不太远的范围内更新。
常见错误
注意:强化学习策略可能会因不当行为约束设置而偏离预期路径,应确保行为策略与参考策略一致。
💡启发点
- 行为约束在强化学习中的应用如何影响模型的稳定性?
- 如何选择合适的参考策略以避免策略偏离?
思考
- 在不同NLP任务中,如何调整MDP建模以获得最佳结果?
- 行为约束是否可以应用于其他领域的强化学习任务?
- 如何评估行为约束对模型性能的影响?
行动清单
- 研究MDP建模与强化学习在其他领域的应用。
- 实验不同行为约束策略对模型效果的影响。
- 开发更有效的奖励函数以提高模型性能。
后续追踪
- 探讨如何在复杂NLP任务中实现更精确的MDP建模。
- 研究行为约束对长期策略稳定性的影响。
原始出处:[选取内容]