RLHF研究方法及研究总结
人类偏好建模与奖励函数优化:RLHF方法
分类:人工智能、机器学习
标签:人类偏好、奖励函数、RL算法
日期:2025年4月12日
核心观点总结
在研究中,算法通过拟合奖励函数与人类偏好,并使用强化学习(RL)算法训练策略,以优化当前预测的奖励函数。人类通过比较智能体行为轨迹片段来提供偏好标签,而不是绝对数值分数。此方法利用了人类更容易进行比较的特性,帮助学习人类偏好。
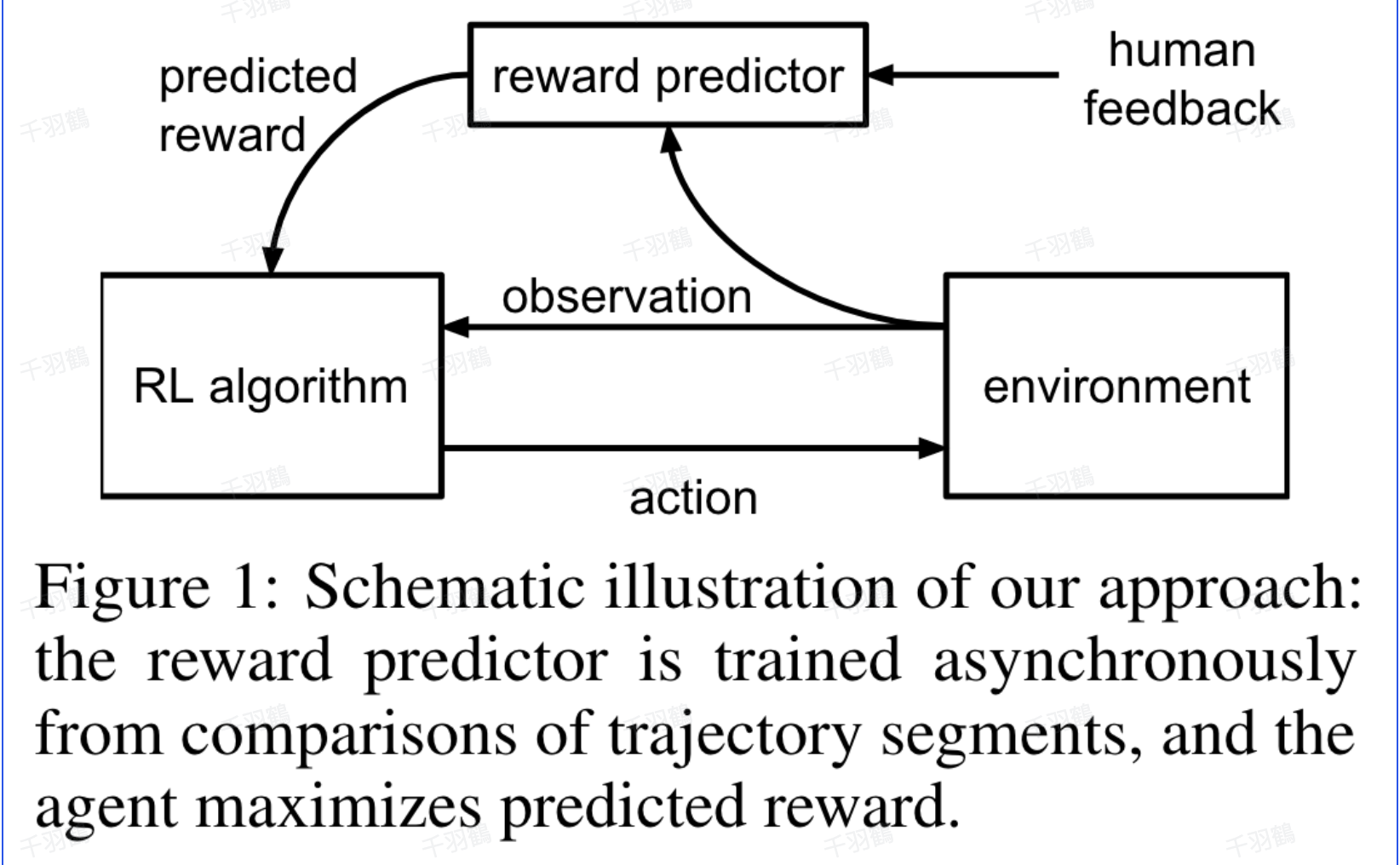
重点段落
-
偏好标签与建模
对于两个智能体轨迹片段和 ,偏好标签 可以表示为 0, 1 或 0.5,分别对应 更被偏好、 更被偏好或两者同等偏好。 -
偏好建模方法
假设人类偏好一个片段的概率与潜在奖励在该片段长度上的总和呈指数关系。基于 Bradley-Terry 模型,可以得出人类偏好片段超过 的概率: -
奖励学习与优化
收集到的人类偏好标签可以通过二分类思路来学习奖励函数,损失函数采用交叉熵:
操作步骤
- ✅ 提供智能体行为轨迹的片段给人类进行比较。
- ⚠ 根据人类反馈的偏好标签构建奖励函数。
- ❗ 使用交叉熵损失函数进行优化,得到符合人类偏好的奖励函数。
常见错误
⚠ 在收集人类偏好标签时,确保数据的多样性和代表性,以避免偏差。
💡 启发点
- 利用人类偏好进行奖励函数优化是一种创新的方法,有助于提升AI决策的合理性。
行动清单
后续追踪
- 后续研究计划包括探索如何在更复杂的环境中应用该方法,以及研究不同偏好标签对学习效果的影响。
原始出处:研究方法与算法描述文档
通过这种方法,我们能够更好地理解和应用人类偏好,从而提升人工智能系统的表现和用户满意度。