Reference-Model
强化学习中的KL约束与奖励机制解析
分类:人工智能
标签:强化学习、PPO算法、KL约束
日期:2025年4月12日
核心观点总结
在强化学习中,KL约束被用于防止策略偏离预训练模型太远。通过冻结SFT模型参数并在PPO训练中加入per-token的KL约束项,确保策略的稳定性。奖励机制通过调整公式,使得新的token-level reward能够更准确地反映策略的有效性。
重点内容
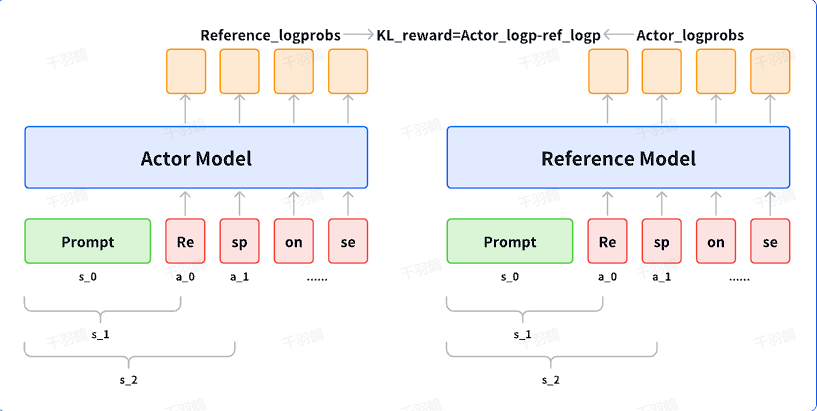
KL约束在PPO训练中的应用
在PPO训练过程中,冻结SFT模型的参数,并利用其产生per-token的KL约束项。这种机制旨在防止策略过度偏离SFT模型,确保训练过程中策略的稳定性。
奖励机制的调整
新的奖励公式可以表示为:
其中,token-level reward根据时间状态进行区分。
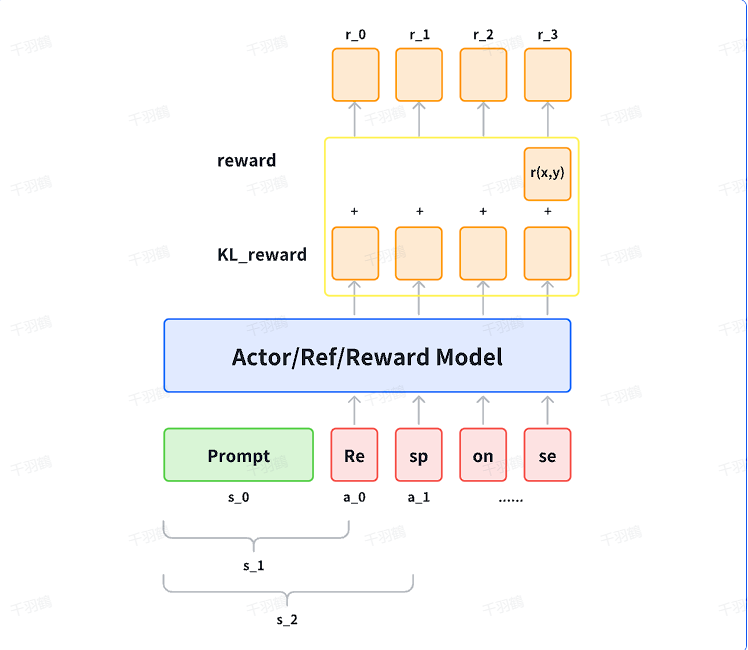
奖励公式的具体表达
-
当
时: -
当
时:
其中
操作步骤
- ✅ 冻结SFT模型参数。
- ⚠ 在PPO训练中加入per-token的KL约束项。
- ❗ 调整奖励公式以反映新的策略有效性。
常见错误
⚠ 在训练过程中,忽视KL约束可能导致策略偏离预期结果。
💡 启发点
通过引入KL约束,可以有效地控制策略的偏移,从而提高模型的稳定性和可靠性。
行动清单
- 研究更多关于SFT模型在不同领域应用中的效果。
- 实验不同
值对奖励机制的影响。 - 探索其他可能的约束机制以提升策略稳定性。
原始出处:[文本来源未提供]