Reward-Model
强化学习与大模型奖励模型训练
元数据:
- 分类:机器学习
- 标签:强化学习,奖励模型,PPO,SFT
- 日期:2025年4月12日
核心观点总结
在强化学习中,奖励模型(Reward Model)用于评估生成的响应的质量。在PPO(Proximal Policy Optimization)训练过程中,奖励模型的参数是冻结的,仅用于提供奖励值。本文介绍了奖励模型的训练流程及其与传统强化学习的区别。
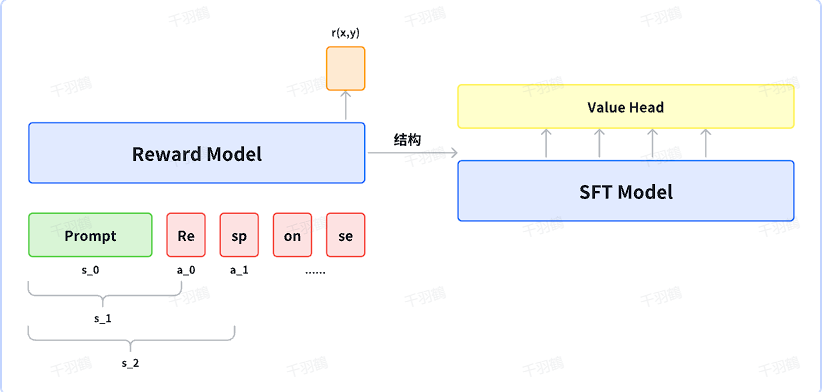
奖励模型训练
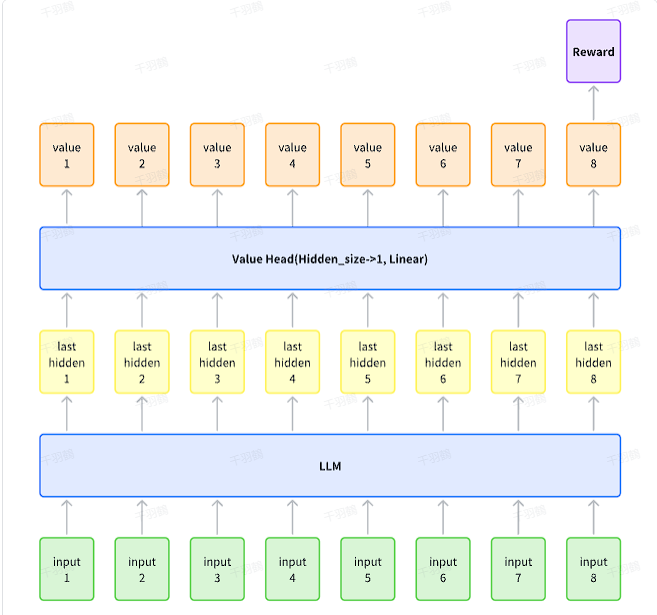
奖励模型通常是在SFT(Supervised Fine-Tuning)模型的基础上,通过添加价值头(Value Head)进行训练。以下是奖励模型训练的关键步骤:
- 奖励计算:只在最后一个token处计算奖励值,作为整个响应的奖励。
- 损失函数:
其中 表示提示(prompt), 表示选择的响应(chosen response), 表示拒绝的响应(rejected response)。
class PairWiseLoss(nn.Module):
"""
Pairwise Loss for Reward Model
"""
def forward(self, chosen_reward, reject_reward, margin):
if margin is not None:
loss = -F.logsigmoid(chosen_reward - reject_reward - margin)
else:
loss = -F.logsigmoid(chosen_reward - reject_reward)
return loss.mean()
与传统强化学习的对比
传统强化学习的RLHF(Reinforcement Learning with Human Feedback)对一条轨迹中的所有状态动作对进行奖励加和,而大模型奖励模型仅针对整个响应提供一个奖励值。
- 传统RLHF损失函数:
聚合操作
可以将传统强化学习中的奖励加和替换为聚合操作
操作步骤
- ✅ 在SFT模型上添加Value Head。
- ⚠️ 训练过程中冻结Reward Model参数。
- ❗ 使用最后一个token的值作为整个响应的奖励。
常见错误
在奖励计算时,误将中间token的值作为最终奖励。
💡启发点
- 将prompt到response视为单步MDP(Markov Decision Process),这简化了模型的复杂性。
行动清单
- 探索更多聚合操作在奖励模型中的应用。
- 研究不同reward model在PPO中的表现差异。
原始出处:[原文链接或书名章节]