大模型结构与混合专家(LLM & MoE)解析
元数据
- 分类:人工智能/大语言模型
- 标签:大语言模型、混合专家、Transformer、MoE
- 日期:2025年4月8日
核心内容总结
本文解析了大语言模型(LLM)的四种主要结构及其特点,同时介绍了混合专家(MoE)架构的设计理念和技术细节。文章还探讨了不同模型结构在理解和生成任务中的应用场景,以及如何通过 MoE 提升模型性能与计算效率。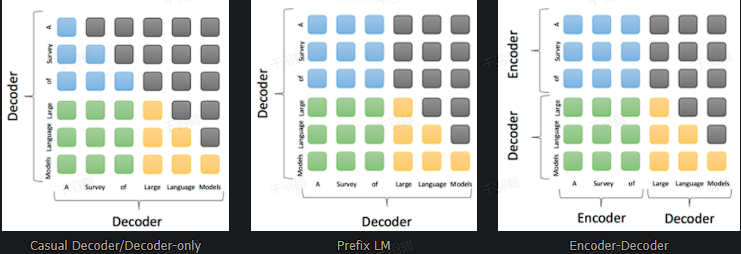
模型结构分类
Decoder-only 模型
- 特点:
- 使用单向注意力机制(从左到右)。
- 模型训练和下游应用一致,适合文本生成任务。
- 高效的训练流程,具备强大的零样本(zero-shot)能力。
- 典型模型:GPT、Llama、BLOOM、OPT
Encoder-only 模型
- 特点:
- 以语言表征为目标,主要用于提取文本特征。
- 适合理解任务,但生成能力较弱。
- 典型模型:BERT
Encoder-Decoder 模型
- 特点:
- 输入采用双向注意力,输出为单向注意力。
- 在需要深度理解的任务上表现更优,但训练效率低,文本生成效果一般。
- 典型模型:T5、Flan-T5、BART
Prefix LM(前缀语言模型)
- 特点:
- 可以看作 Encoder-Decoder 的特例,权衡理解与生成能力。
- 典型模型:GLM、U-PaLM
混合专家(MoE)架构
什么是 MoE?
MoE 是一种通过引入多个专家网络(Experts)和门控网络(Gate)来提升计算效率的模型架构。其核心思想是根据输入特征选择性地激活部分专家网络参与计算,而非所有网络。
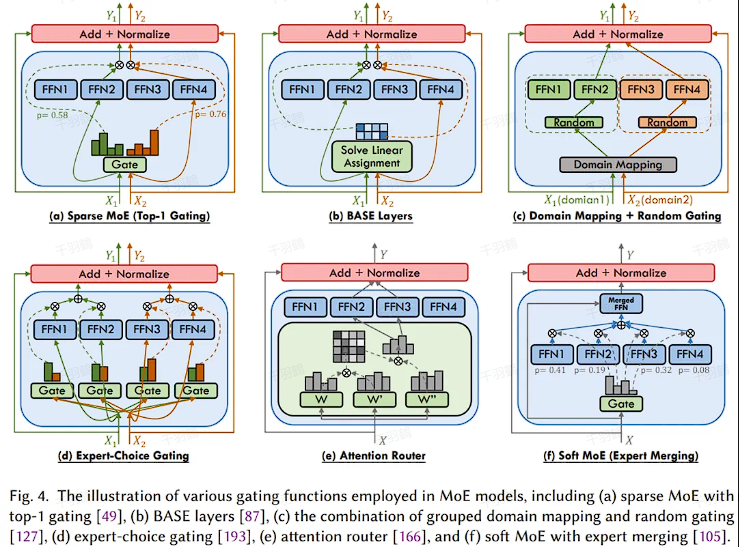
构成要素
- 专家网络:多个独立的子网络,专注于处理特定类型的输入。
- 门控网络:
- 通过 Softmax 激活函数选择合适的专家网络。
- 有三种模式:
- 稀疏式:仅激活部分专家。
- 密集式:激活所有专家。
- Soft 式:可微分的融合方法。
放置位置
MoE 层通常放置在 Transformer 模块中的自注意力(SA)子层之后,用于优化前向传播网络(FFN)的计算效率。
应用场景
在参数量极大的模型中,例如 PaLM(5400 亿参数),MoE 能显著降低计算成本。PaLM 的 FFN 层占据了总参数量的 90%。
常见错误
⚠ 误区提醒:将 MoE 的稀疏激活机制误解为随机选择专家,而非基于输入特征的动态路由。
操作步骤
- ✅ 选择模型架构:根据任务需求选择 Decoder-only、Encoder-only 或 Encoder-Decoder 等架构。
- ✅ 设计 MoE 层:
- 确定专家网络数目 $$N$$。
- 定义门控网络的类型(稀疏式、密集式或 Soft 式)。
- ❗ 优化放置位置:
- 将 MoE 层嵌入 Transformer 的自注意力子层之后。
- ✅ 测试与调优:
- 使用不同任务场景验证模型性能,例如生成与理解任务。
数据表格示例
| 模型类型 | 注意力机制 | 优势 | 典型模型 |
|---|---|---|---|
| Decoder-only | 单向注意力 | 文本生成强,效率高 | GPT、Llama |
| Encoder-only | 双向注意力 | 表征提取优,理解能力强 | BERT |
| Encoder-Decoder | 双向(输入)+单向(输出) | 深度理解,适合问答任务 | T5、BART |
| Prefix LM | 特殊的 Encoder-Decoder | 平衡理解与生成能力 | GLM、U-PaLM |
📈 趋势预测
- 随着模型参数量的持续增长,MoE 将成为提升计算效率的核心技术之一。
- 更高效的稀疏门控机制可能会被开发,用于进一步减少计算成本。
- Prefix LM 或类似架构可能在多模态任务中获得更广泛应用。
💡 启发点
- MoE 架构通过“选择性激活”提升了大模型的效率,这是解决超大规模计算瓶颈的关键思路。
- 不同任务场景对模型架构提出了差异化需求,未来可能会出现更多“混合型”架构。
[思考] 延伸问题
- 如何改进现有的稀疏门控机制,使其更高效且不损失性能?
- 在小规模数据集上,是否存在轻量化 MoE 的实现方案?
- Prefix LM 是否可以进一步优化以提升训练效率?
行动清单
- 学习并实现一个简单的 MoE 模型,测试其在小规模数据集上的效果。
- 深入研究 Prefix LM 的架构设计,探索其在多模态任务中的潜力。
- 跟踪最新的 LLM 和 MoE 技术发展动态。
来源:整理自技术文档《大模型结构与混合专家》