解码采样策略:Greedy Search与Beam Search的实现与优化
分类:自然语言处理
标签:解码策略、大模型生成、Beam Search
日期:2025年4月1日
核心观点总结
在自然语言处理领域,大模型生成文本时需要选择解码策略以确保生成的质量和多样性。本文主要探讨了两种主流解码策略——Greedy Search和Beam Search,并通过代码示例展示了Beam Search的具体实现细节。
- Greedy Search:每次选择概率最大的词,简单但可能导致生成结果单调重复。
- Beam Search:维护多个候选序列,通过概率平衡质量与多样性,但可能显得保守。
解码策略详解
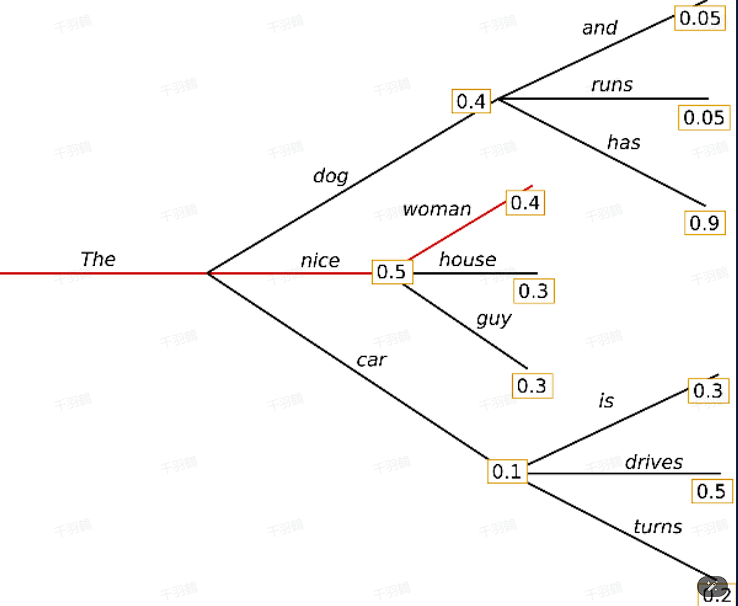
Greedy Search
- 特点:
✅ 每次选择概率最高的词
⚠ 简单高效,但可能生成单调、重复的文本
💡 启发点:适合简单任务,但对复杂生成任务效果欠佳。
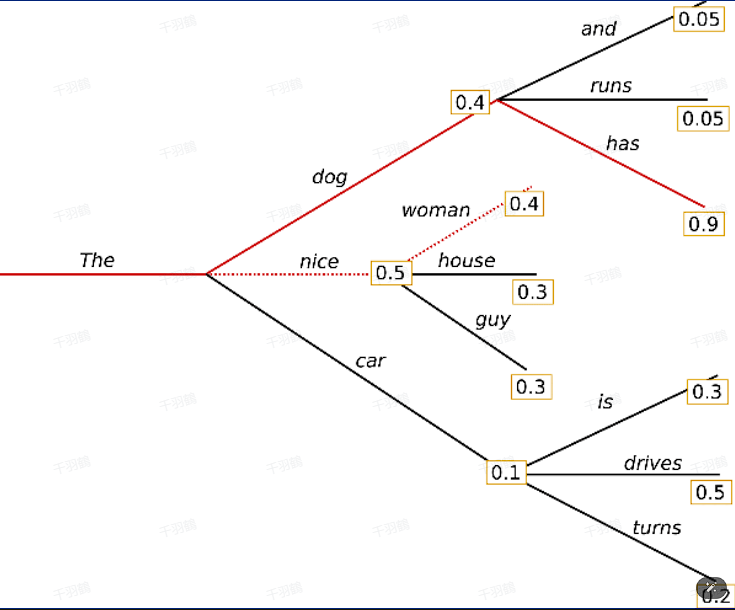
Beam Search
-
核心机制:
✅ 维护一个大小为 $$k$$ 的候选序列集合
✅ 每一步从每个候选序列的概率分布中选择概率最高的 $$k$$ 个词
✅ 保留总概率最高的 $$k$$ 个候选序列 -
代码实现:
def process(input_ids, next_scores, next_tokens, next_indices):
batch_size = 3
group_size = 3
next_beam_scores = torch.zeros((batch_size, num_beams), dtype=next_scores.dtype)
next_beam_tokens = torch.zeros((batch_size, num_beams), dtype=next_tokens.dtype)
next_beam_indices = torch.zeros((batch_size, num_beams), dtype=next_indices.dtype)
for batch_idx in range(batch_size):
beam_idx = 0
for beam_token_rank, (next_token, next_score, next_index) in enumerate(
zip(next_tokens[batch_idx], next_scores[batch_idx], next_indices[batch_idx])
):
batch_beam_idx = batch_idx * num_beams + next_index
next_beam_scores[batch_idx, beam_idx] = next_score
next_beam_tokens[batch_idx, beam_idx] = next_token
next_beam_indices[batch_idx, beam_idx] = batch_beam_idx
beam_idx += 1
return next_beam_scores.view(-1), next_beam_tokens.view(-1), next_beam_indices.view(-1)
# 示例调用
input_ids = torch.randint(0, 100, size=(3, 1))
input_ids, beam_scores = beam_search(input_ids, max_length=10, num_beams=3)
print(input_ids)
💡 启发点:通过维护多个候选序列,Beam Search能有效提升生成质量,但代价是计算复杂度更高。
常见错误警告
⚠ 注意事项:
- Beam大小($$k$$)过小可能导致生成结果质量下降;过大则增加计算成本。
- Beam Search可能过于保守,导致缺乏创造性生成。
数据与公式
数据表格示例
| 解码策略 | 优势 | 劣势 |
|---|---|---|
| Greedy Search | 简单高效 | 单调、重复 |
| Beam Search | 平衡质量与多样性 | 保守、不自然 |
公式示例
Beam Search核心公式:
[思考] 延伸问题
- 如何结合两种解码策略,设计出既高效又多样化的生成算法?
- 在实际应用中,是否可以动态调整Beam大小以适配不同任务?
- 是否有更先进的解码策略能解决Beam Search的保守问题?
来源:整理自自然语言处理相关技术文档与代码示例。
行动清单
- 实现Greedy Search和Beam Search的代码并测试不同参数对生成效果的影响。
- 阅读相关论文,探索改进Beam Search的技术方案,例如Top-p或Top-k采样。
- 应用上述解码策略于实际项目,评估其性能和生成质量。
📈 趋势预测
未来解码策略将更注重结合概率分布与上下文语义,利用动态调整机制提升生成效果,同时减少计算开销。
后续追踪
- 研究Top-p采样和温度调节对生成质量的影响。
- 探索基于强化学习优化解码策略的新方法。