激活函数详解与比较:从Sigmoid到Swish
元数据
- 分类:深度学习基础
- 标签:激活函数、梯度消失、ReLU、Swish
- 日期:2025年3月2日
内容摘要
在深度学习中,激活函数是神经网络的核心组件之一,它决定了神经元的输出以及模型的学习能力。本文对常见的激活函数进行了总结,包括它们的优缺点、公式以及适用场景。
常见激活函数解析
以下是完善后的公式格式,确保在Obsidian中正常显示:
Sigmoid
- 公式:
- 优点:
- 能够将输入值映射到
之间,适合二分类问题。
- 能够将输入值映射到
- 缺点:
- 梯度消失问题:当输入值较大或较小时,梯度接近于
,导致训练效率低下。 - 输出非零中心:权重更新可能偏向特定方向。
- 指数运算耗费计算资源。
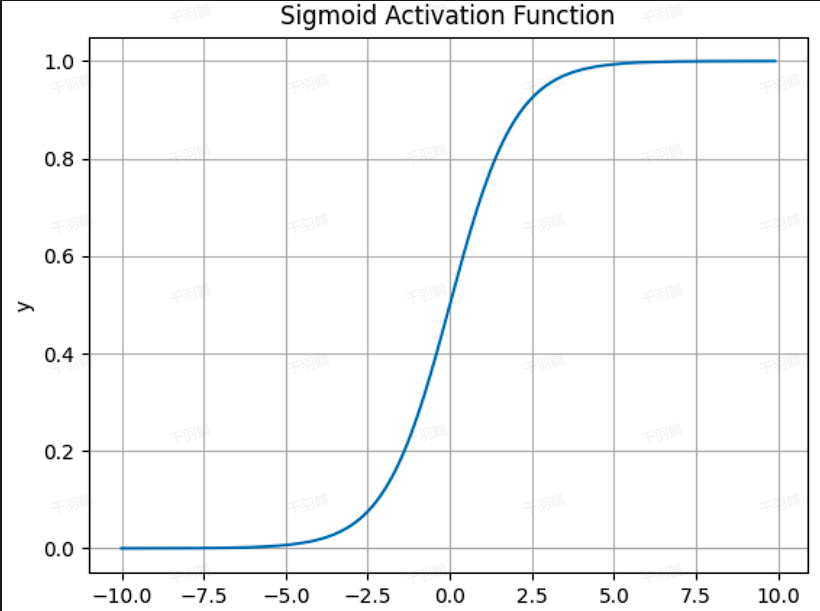
- 梯度消失问题:当输入值较大或较小时,梯度接近于
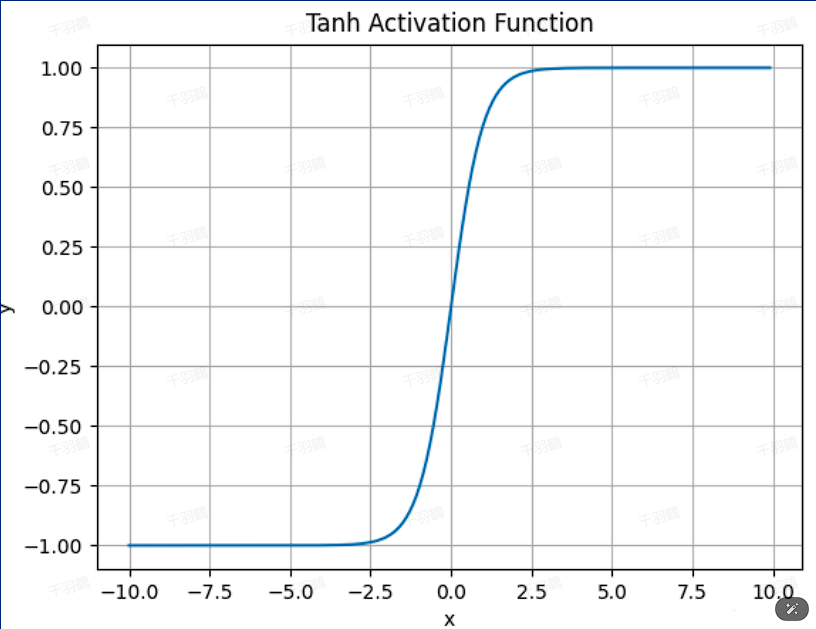
Tanh
- 公式:
- 优点:
- 输出值在
之间,零为中心,权重更新更稳定。
- 输出值在
- 缺点:
- 梯度饱和问题仍然存在。
- 同样需要指数运算,计算资源消耗较大。
ReLU
- 公式:
- 优点:
- 解决了梯度消失问题,输入为正时不会饱和。
- 计算简单,不需要指数运算。
- 缺点:
- Dead ReLU 问题:当输入为负时,梯度为
,导致神经元“死亡”,无法更新参数。
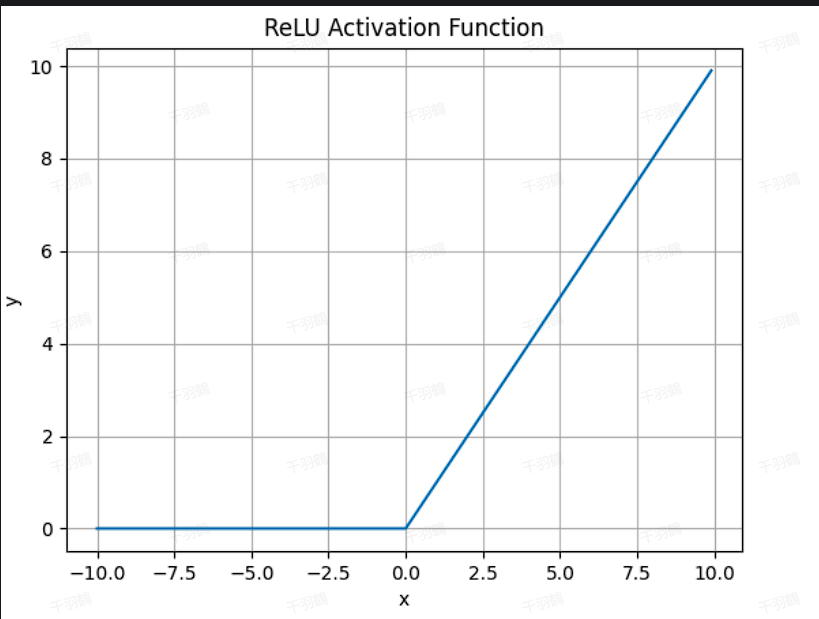
- Dead ReLU 问题:当输入为负时,梯度为
Leaky ReLU
- 公式:
- 优点:
- 改进了 ReLU 的 Dead ReLU 问题,使负输入也能产生非零梯度。
- 缺点:
- 参数
需要人工设置。 - 在复杂分类任务中表现可能不够优秀。

- 参数
ELU
- 公式:
- 优点:
- 输出均值接近零,加快学习速度。
- 对较小输入饱和至负值,有助于减少前向传播的变异。
- 缺点:
- 指数运算导致计算效率较低。
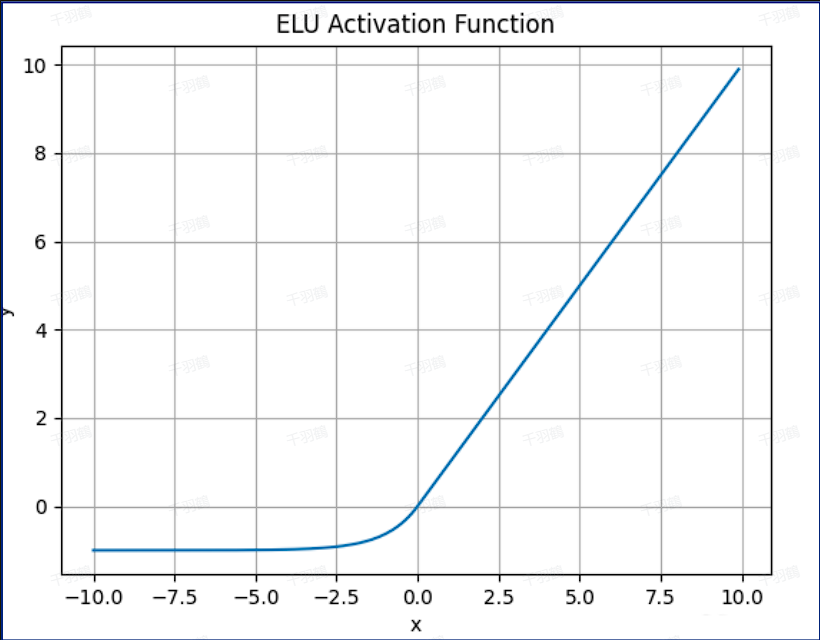
- 指数运算导致计算效率较低。
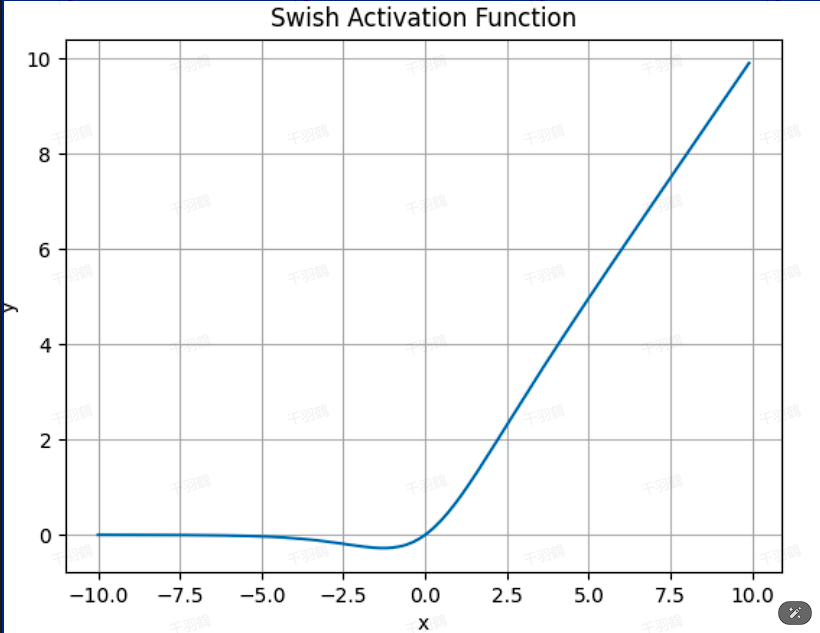
Swish
- 公式:
- 优点:
- 无界性防止训练过程中梯度过早饱和。
- 有界性增强正则化能力,减少过拟合。
- 在复杂任务中表现更优。
- 缺点:
- 相较 ReLU,计算复杂度稍高。
激活函数优缺点对比表
| 激活函数 | 优点 | 缺点 |
|---|---|---|
| Sigmoid | 简单易用,适合二分类问题 | 梯度消失,输出非零中心,计算资源消耗大 |
| Tanh | 零为中心,权重更新更稳定 | 梯度饱和问题,指数运算耗费资源 |
| ReLU | 快速收敛,解决梯度消失问题 | Dead ReLU问题,输出非零中心 |
| Leaky ReLU | 改善Dead ReLU问题,负输入有梯度 | α需人工设置,复杂分类效果一般 |
| ELU | 输出均值接近零,加快学习速度 | 指数运算效率低 |
| Swish | 强正则化能力,无界性防止梯度饱和,适合复杂任务 | 相较ReLU计算复杂度稍高 |
常见错误与警示区块
⚠️ 常见错误:
- 忽略激活函数选择对模型性能的影响。
- 在数据量较小时使用耗资源的激活函数(如ELU)。
- 未处理Dead ReLU问题导致部分神经元无效。
行动清单
✅ 确认任务类型(分类/回归)选择合适激活函数。
✅ 在调试过程中观察梯度变化是否出现梯度消失或爆炸。
✅ 尝试不同激活函数组合以优化模型性能。
思考与启发
💡 激活函数的选择不仅影响模型性能,还直接影响训练效率。以下是一些值得思考的问题:
- 是否可以设计一个自适应激活函数,根据输入动态调整参数?
- Swish是否能完全取代ReLU成为新的默认选择?
- 如何结合激活函数与优化算法进一步提升模型收敛速度?
来源:深度学习相关文档与技术资料整理