训练Tokenizer
元数据
- 分类:自然语言处理(NLP)
- 标签:中文预训练、Tokenizer、语言模型优化
- 日期:2023-10-12
核心内容总结
在构建中文语言模型时,预训练流程是关键步骤之一。其中,Tokenizer的训练与优化直接影响模型的性能与适用性。本文将重点解析如何通过词表扩充、压缩率控制等方式优化Tokenizer,并探讨中文预训练的独特挑战与解决方案。
重点内容解析
Tokenizer的作用与训练方法
Tokenizer(分词器)的主要作用是将输入的句子切分为词或字,并将这些切分结果转化为模型可理解的token。这是预训练模型的第一步。
✅ Tokenizer训练步骤:
- 选择算法:使用BPE(Byte Pair Encoding)、BBPE(Balanced Byte Pair Encoding)或WordPiece算法。
- 数据准备:收集通用大规模数据集和业务场景相关数据。
- 环境需求:需要内存较大的CPU机器。
- 压缩率控制:保持1个token约对应1.5个汉字以平衡解码效率与模型知识能力。
- 词表扩充:手动添加常见汉字或业务场景相关词汇。
💡启发点:压缩率过低会导致解码效率低,而压缩率过高会影响模型知识表达能力,因此需要找到一个平衡点。
中文预训练的独特挑战
许多优秀的语言模型在中文任务上的表现不佳,因为它们的预训练主要基于英文语料。为解决这一问题,研究者通常会对英文模型进行二次预训练。
⚠ 常见问题:
- 数字切分错误(如“9.9 > 9.11”问题)。
- 词表中敏感或脏token未移除。
- 业务场景相关token覆盖不足。
词表扩充实例对比
通过对比Chinese-LLaMA与原始LLaMA的Tokenizer,可以发现:
- Chinese-LLaMA新增了17953个tokens,大部分为汉字。
- BELLE模型在120万行中文文本上训练了一个规模为5万的token集合,并将其与原始LLaMA词表合并。
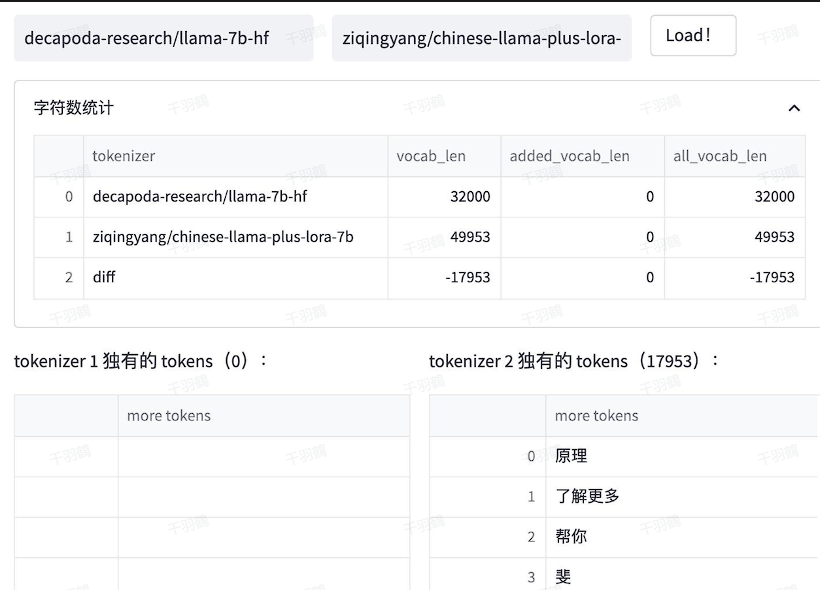
📊 数据表格示例:
| 模型名 | 新增tokens数量 | 数据规模 |
|---|---|---|
| Chinese-LLaMA | 17953 | 未明确 |
| BELLE | 50000 | 120万行文本 |
💡启发点:通过扩充词表,可以有效降低模型训练难度,提升其适用于中文任务的能力。
技术术语通俗解释
- BPE/BBPE/WordPiece算法:一种将文本切分为小单位(如词或字)的方法,用于构建Tokenizer。
- 压缩率:指一个token平均对应多少个汉字,影响解码效率和模型知识能力。
- 词表扩充:手动添加常见汉字或特定领域词汇,以优化模型性能。
[思考]板块
- 如何进一步优化Tokenizer以支持多语种任务?
- 是否可以设计一种动态调整压缩率的方法以适应不同任务场景?
- 在中文预训练中,如何平衡通用性与领域专用性?
原始出处:本文内容基于某技术文档关于中文语言模型预训练与Tokenizer优化的部分内容整理与总结。
常见错误警告区块
⚠ 注意事项
- 数字切分问题需特别关注,避免影响模型回答准确性。
- 词表扩充时需确保覆盖足够的中英词汇,同时避免加入敏感或无意义的token。
行动清单
- 收集更大规模的中文数据集以支持Tokenizer训练。
- 针对业务场景设计定制化词表扩充策略。
- 测试不同压缩率对模型性能的影响,寻找最佳平衡点。
📈趋势预测
随着中文语言模型需求的增加,未来可能出现:
- 更高效的中文Tokenizer算法。
- 动态调整词表大小和压缩率的技术。
- 支持多语种任务的统一预训练框架。
后续追踪方向
- 对比不同中文大模型在实际任务中的表现。
- 探索如何在低资源环境下实现高质量中文预训练。
- 调研针对小语种任务的词表扩充策略。