GRPO
深入探索PPO优化:减少模型数量与计算资源
分类:自动推断为机器学习与强化学习
标签:PPO优化、GRPO、强化学习、Actor-Critic、LLM
日期:2025年4月12日
在强化学习领域,PPO(Proximal Policy Optimization)算法是一个重要的工具。然而,当应用于大规模语言模型(LLM)时,PPO的实现需要大量计算资源。因此,本文探讨了如何通过减少模型数量来优化PPO。
核心观点
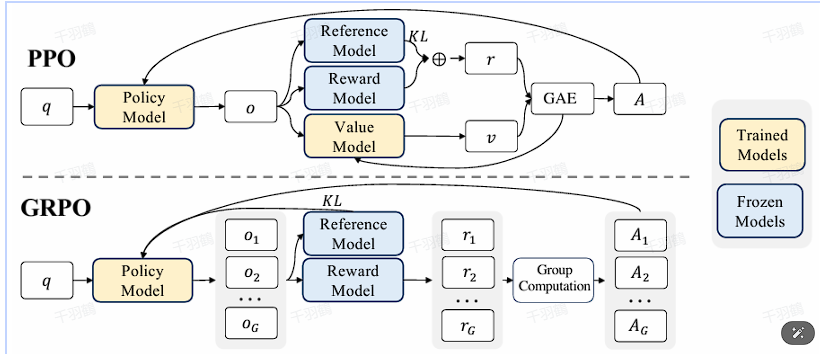
在PPO的实现中,通常需要四个模型:Actor、Critic、Reference和Reward。本文提出的一种优化思路是减少这些模型的数量,以降低计算资源的需求。
重点段落
-
PPO的四个关键模型:在传统环境中,Actor、Critic和Reference是简单的网络实现,而Reward是环境自带的规则设计。然而,在LLM中,这些模型都基于LLM初始化或改进,导致资源需求增加。
-
去掉Reference model的考虑:如果去掉Reference model,算法将退化为最大熵强化学习。Reference model的作用是防止策略偏离参考策略,因此通常建议保留。
-
替换Reward model的可能性:如果用基于规则的奖励替换Reward model,就不需要单独训练一个Reward model,但奖励在公式中仍然不可或缺。
-
去掉Critic model的可能性:探索能否通过某种替换去掉Critic model。策略梯度、Actor-Critic和PPO算法都依赖于一个基于奖励的值来指导策略优化方向。
-
GRPO的创新点:GRPO(Group Relative Policy Optimization)是一种去掉Critic model的方法,通过重新定义优势函数来实现。
技术术语转述
- Actor model:负责决策的模型。
- Critic model:评估当前策略性能的模型。
- Reference model:用于保持策略不偏离参考标准。
- Reward model:提供奖励信号以指导策略优化。
- 优势函数(Advantage Function):用于衡量当前动作相对于平均动作价值的优劣。
操作步骤
- ✅ 识别需要保留的模型:Actor model是必须保留的。
- ⚠ 评估Reference model的重要性:考虑其对策略偏离的影响。
- ❗ 探索Reward model替换方案:尝试基于规则的奖励系统。
- ✅ 研究去掉Critic model的方法:利用GRPO进行尝试。
常见错误
⚠ 在减少模型数量时,可能会忽视某些模型对策略稳定性的贡献,导致策略偏离或不稳定。
💡启发点
探索GRPO方法去掉Critic model,通过重新定义优势函数来实现策略优化的新方向。
行动清单
- 研究更多关于GRPO的方法与应用。
- 实验不同模型组合对PPO性能的影响。
- 探讨如何在LLM中有效实现基于规则的奖励系统。
原始出处:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
GRPO优势函数估计与奖励监督RL
元数据:
分类:强化学习
标签:GRPO, 强化学习, 奖励函数, 优势函数, ORM
日期:2025年4月12日
核心观点总结
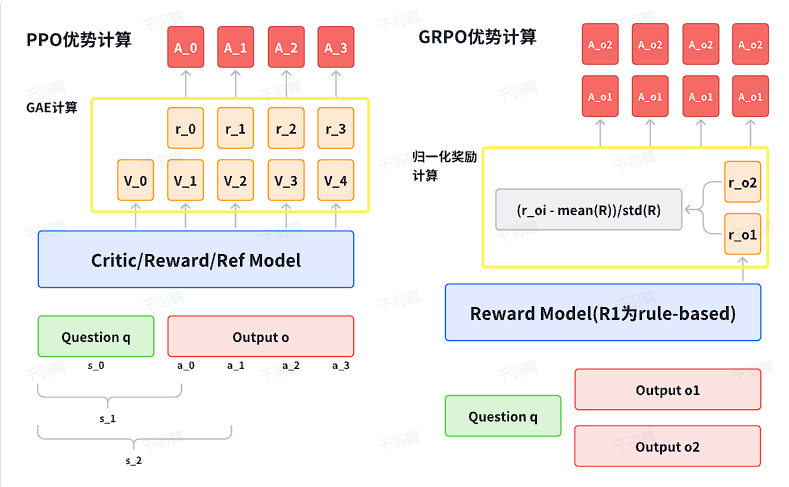
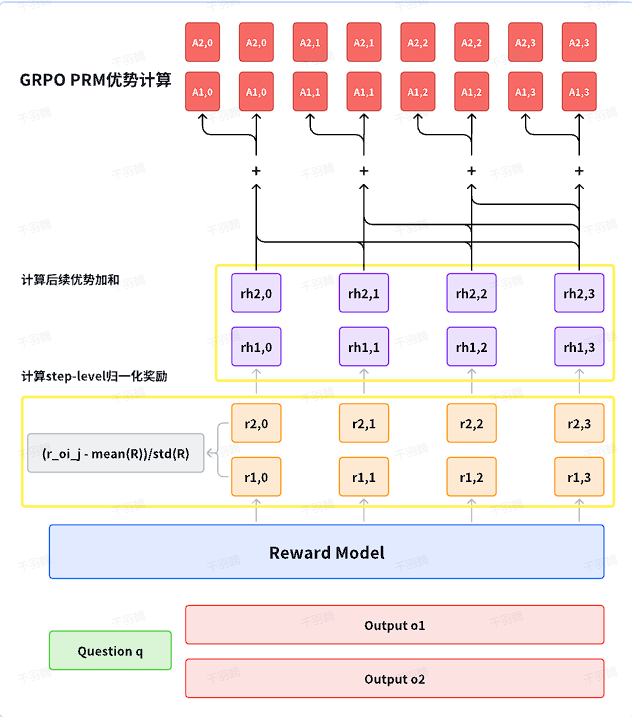
GRPO(Generalized Reward Policy Optimization)通过对同一问题的多组输出进行采样,并使用奖励模型对这些回答给予奖励值,从而估计优势函数。通过传统的ORM(Outcome Reward Model)进行奖励监督强化学习,计算出每个输出的归一化奖励作为优势函数,并应用于每个token。
重点段落
-
优势函数估计:使用奖励模型对采样输出进行奖励值评估,计算出优势函数的估计。公式为:
这里,
是第 个输出的奖励值。
-
价值函数定义:在强化学习中,价值函数定义为回报(折扣累积奖励)的期望。在结果奖励监督RL中,状态是问题
,动作是输出 ,价值函数简化为: -
优势函数应用:GRPO将整个优势值应用于输出中每个token上,使得当前策略更新每个token的条件输出概率时,更新幅度和方向一致。
操作步骤
- ✅ 对同一问题进行多组输出采样。
- ⚠ 使用奖励模型对采样输出进行奖励值评估。
- ❗ 计算出归一化奖励作为优势函数,并应用于每个token。
常见错误
⚠ 在计算归一化奖励时,确保采样组足够大以保证估计的准确性。
💡 启发点
将整个输出的优势值应用于每个token上,使得策略更新时保持一致性,这是GRPO的一大创新。
行动清单
- 研究如何提高采样组的数量和质量。
- 探讨其他可能的奖励模型以优化GRPO。
- 实验不同的策略更新方法对优势函数应用的影响。
数据转换
| 输出序号 | 奖励值 |
归一化奖励 |
|---|---|---|
| 1 | ||
| 2 | ||
| ... | ... | ... |
| G |
原始出处:内容来源于GRPO相关技术文档。
GRPO策略更新与实现:深度学习中的强化学习优化
分类:深度学习
标签:GRPO, 强化学习, 策略优化, 代码实现
日期:2025年4月12日
GRPO(Generalized Reinforcement Policy Optimization)是一种用于强化学习的策略更新方法。本文将探讨GRPO的核心公式、实现代码及其与PPO(Proximal Policy Optimization)的区别。
GRPO策略更新公式
GRPO的策略更新公式如下:
💡 启发点:GRPO通过引入无偏估计的KL散度来优化策略,区别于PPO将KL散度约束项加到奖励值中。
代码实现
以下是GRPO在 trl 库中的代码实现的核心部分:
def _prepare_inputs(self, inputs: dict[str, Union[torch.Tensor, Any]]) -> dict[str, Union[torch.Tensor, Any]]:
device = self.accelerator.device
prompts = [x["prompt"] for x in inputs]
prompts_text = [maybe_apply_chat_template(example, self.processing_class)["prompt"] for example in inputs]
prompt_inputs = self.processing_class(
prompts_text, return_tensors="pt", padding=True, padding_side="left", add_special_tokens=False
)
prompt_inputs = super()._prepare_inputs(prompt_inputs)
prompt_ids, prompt_mask = prompt_inputs["input_ids"], prompt_inputs["attention_mask"]
if self.max_prompt_length is not None:
prompt_ids = prompt_ids[:, -self.max_prompt_length:]
prompt_mask = prompt_mask[:, -self.max_prompt_length:]
with unwrap_model_for_generation(self.model, self.accelerator) as unwrapped_model:
prompt_completion_ids = unwrapped_model.generate(
prompt_ids, attention_mask=prompt_mask, generation_config=self.generation_config
)
prompt_length = prompt_ids.size(1)
prompt_ids = prompt_completion_ids[:, :prompt_length]
completion_ids = prompt_completion_ids[:, prompt_length:]
prompt_mask = prompt_mask.repeat_interleave(self.num_generations, dim=0)
is_eos = completion_ids == self.processing_class.eos_token_id
eos_idx = torch.full((i...
常见错误
⚠ 警告:在实现GRPO时,需确保KL散度的无偏估计准确,否则可能导致策略更新不稳定。
行动清单
- ✅ 理解GRPO与PPO的区别及其应用场景。
- ❗ 确保在实际应用中,准确实现KL散度的无偏估计。
- ⚠ 检查代码实现中的参数配置,特别是
\epsilon和的值。
原始出处:trl库中的GRPO实现
GRPO代码优化与重要性采样分析
分类:自动推断为技术博客
标签:GRPO, 代码优化, 强化学习, PPO
日期:2025年4月12日
核心观点总结
本文探讨了在GRPO(Gradient Reinforcement Policy Optimization)代码中重要性采样处理的不足之处。传统的PPO(Proximal Policy Optimization)算法通常会通过多次更新策略来提高样本效率,而当前实现的TRL(Transformer Reinforcement Learning)版本则只更新一次,导致样本效率较低。由于新旧策略相同,重要性权重始终为1,因此不需要进行clip操作。
重点段落
重要性采样的不足
在compute_loss函数中,重要性采样直接使用了公式:
这种实现没有进行clip操作,因为当前策略与旧策略相同,导致重要性权重为1。
PPO的重要性采样处理
传统PPO代码会对一批样本更新多个epoch,初始时新旧策略相同,但后续更新中旧策略保持不变,从而提高样本效率。这种方法避免了新旧策略一致的情况。
TRL实现的简化
TRL实现中省略了多次更新epoch的步骤,仅更新一次,因此不需要clip操作。梯度通过优势函数和KL项提供信号:
操作步骤
✅ 计算每个token的log概率
⚠ 确保策略更新次数
❗ 关注梯度回传
常见错误
警告:在重要性采样中忽略clip操作可能导致梯度计算错误,影响模型训练效果。
示例代码
def compute_loss(self, model, inputs, return_outputs=False, num_items_in_batch=None):
# Compute the per-token log probabilities for the model
prompt_ids, prompt_mask = inputs["prompt_ids"], inputs["prompt_mask"]
completion_ids, completion_mask = inputs["completion_ids"], inputs["completion_mask"]
💡 启发点:通过多次更新epoch可以显著提高样本效率。
行动清单
数据转换
目前没有具体数据内容需要转换。
原始出处:本文内容改编自现有技术文档和代码示例。