深度解析语言模型采样方法:Top-K、Top-P、Temperature及综合策略
元数据:
分类: 自然语言处理
标签: 语言模型、采样方法、AI生成技术
日期: 2025年4月1日
什么是语言模型采样方法?
在生成式语言模型中,采样方法决定了输出文本的多样性和质量。这些方法通过调整模型选择词语的概率分布,来平衡生成内容的随机性与稳定性。以下是几种主流采样技术的核心概念及应用场景。
Top-K Sampling
核心概念:
Top-K Sampling 是一种从排名靠前的 k 个词中随机选择的方法。它允许高概率词语有更大的被选中机会,同时保留一定的随机性。这种方式可以提升生成质量,但也可能在以下两种情况下出现问题:
- 分布尖锐时:可能导致生成内容不连贯或胡言乱语。
- 分布平坦时:限制了模型的创造力。

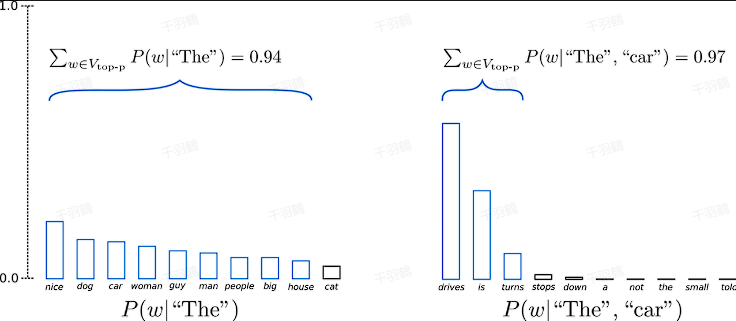
Top-P Sampling
核心概念:
Top-P Sampling(又称核采样)通过累积概率设定一个阈值 $$P$$,从满足该阈值的最小词集合中随机采样。这种方式动态调整候选词集合大小,更适合应对概率分布变化较大的场景。
代码实现:
masked_probs = torch.gather(probs, dim=-1, index=sorted_indices[:, :cutoff_idx + 1])
# 重新归一化剩余概率
masked_probs = masked_probs / masked_probs.sum(dim=-1, keepdim=True)
# 从候选词中随机选择一个词
selected_idx = torch.multinomial(masked_probs, 1)
return sorted_indices.gather(-1, selected_idx)
Temperature Sampling
核心概念:
通过调整 Softmax 的温度系数来影响输出词的概率分布:
- 温度高(如 $$T > 1$$):概率分布更平坦,生成更随机。
- 温度低(如 $$T < 1$$):概率分布更集中,生成更稳定。
这种方法适用于需要控制生成文本风格和随机程度的场景。
综合采样策略:KPT
核心概念:
KPT 是一种结合 Top-K、Top-P 和 Temperature 的综合方法,逐步进行采样以提升生成效果。通过多层筛选,KPT 能在保持随机性的同时提高生成质量。
多答案选择策略
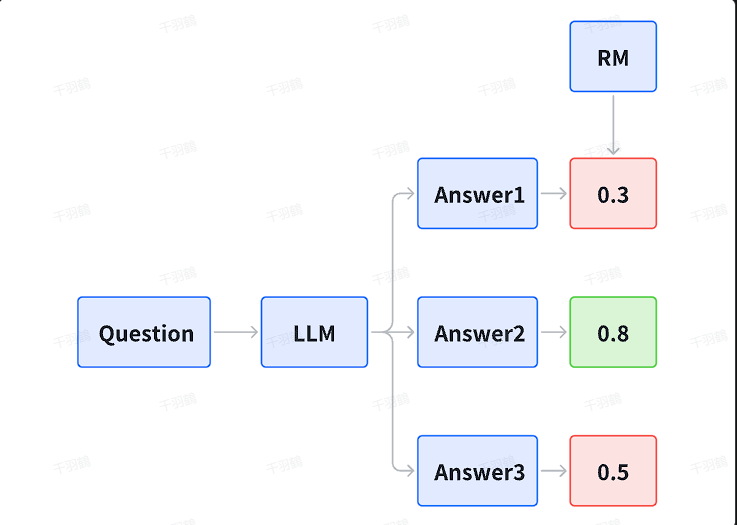
Best-of-N
让模型生成 N 个回答,通过评分机制(如 Verifier 或 PRM)选择得分最高的答案作为最终结果。
Majority Vote
让模型输出多个答案,以一致性最多的答案作为最终结果。
Self-consistency
通过生成多个推理路径,再用多数投票选出最合理的答案。这种方法在复杂推理任务中表现尤为突出。
常见错误 ⚠️
- 参数设置不当:
- K 值过小可能导致生成内容单一。
- P 值过大可能引入低质量候选词。
- 温度过高可能使输出过于随机。
- 忽略采样方法组合:单一方法可能难以应对复杂场景,需结合多种策略。
💡启发点
- 动态调整采样参数:根据任务需求实时调整 K、P 和温度值。
- 结合多答案选择策略:提升复杂任务的推理准确性。
📈趋势预测
- 自动化参数优化:未来可能出现基于任务自动调整采样参数的技术。
- 强化学习结合采样策略:通过奖励机制优化生成质量。
行动清单
- 实现不同采样方法的代码,并测试其在文本生成中的效果。
- 探索 KPT 综合采样策略对生成质量的提升。
- 应用 Self-consistency 方法于复杂推理任务。
[思考]延伸问题
- 如何设计动态调整 K 和 P 的算法,使其适应不同场景?
- 是否可以结合语义理解优化采样过程?
- 如何评估生成内容的创造力与准确性之间的平衡?
来源: 原文内容整理自技术文档,部分代码示例来自 PyTorch 实现。