多轮对话专项提升
多轮对话数据构造与优化策略
元数据
- 分类:自然语言处理
- 标签:多轮对话、数据构造、模型优化、伪多轮数据
- 日期:2023年11月1日
核心观点总结
本文讨论了如何通过多轮对话数据的构造和优化来提升对话模型的表现。重点在于如何判断和利用真多轮与伪多轮数据,以及如何通过合成和飞轮机制来增强数据集。此外,还介绍了通过样本拆分和合并来加速计算的策略。
重点段落
多轮对话数据判断
✅ 首先,训练一个小的判别模型来判断session中的每个turn是否连续。连续为1,不连续为0。主题不变的真多轮数据直接加入训练,而主题变化的伪多轮数据则选择性加入,以提高模型学习难度。
多轮对话数据合成
✅ 如果现有数据量不足,可以利用单轮对话合成多轮对话数据。通过第一轮的数据构造第二轮的提示(prompt),可以使用模板或GPT进行合成,然后继续合成回答。
多轮计算loss
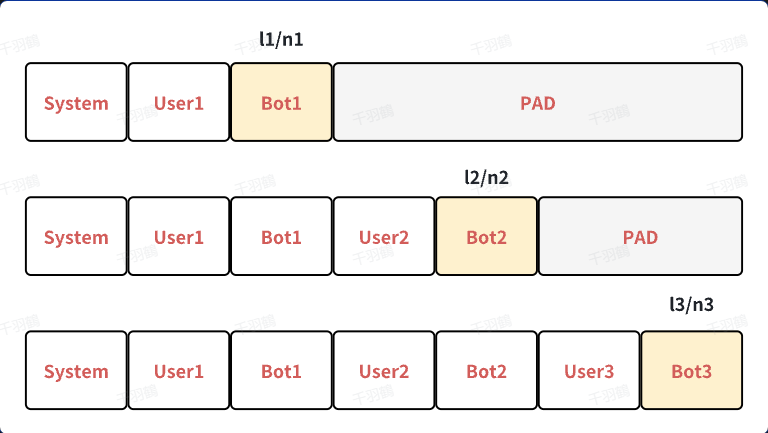
✅ 假设一个对话中有3轮user和bot的交互,可以构建三个样本。计算loss时,只计算bot response部分,公式为:
其中,$$l_i$$表示第$$i$$个样本的loss,$$n_i$$表示第$$i$$个样本输出的token数量。
常见错误
⚠️ 如果将多个样本合并为一个样本进行计算,需注意token_ids和labels的设置,否则会导致loss计算错误。
💡启发点
- 适量伪多轮数据能够有效提升模型的学习能力。
- 数据飞轮机制有助于持续优化模型。
行动清单
- 评估现有对话数据是否符合真多轮和伪多轮的标准。
- 实施数据合成策略以扩大训练集。
- 优化loss计算方法以提高训练效率。
📈趋势预测
随着对话系统需求的增加,未来在多轮对话数据的自动构造和优化方面将会有更多创新技术出现。
后续追踪
- 探索更多关于伪多轮数据对模型影响的实证研究。
- 研究如何更高效地实现多轮对话数据飞轮机制。
[思考]
- 如何进一步提高伪多轮数据的质量?
- 有哪些新的方法可以自动识别和合成多轮对话?
- 在不同应用场景下,多轮对话模型需要做哪些调整?
原始出处:本文内容基于提供的文本进行总结与整理。
多轮对话专项提升2